
Авторизация
Сброс пароля
Автоматизация обработки актов приёма-осмотра (АПО) и экспертиз для одного из крупнейших девелоперов страны
Заказчик: NDA

Ручная обработка актов приёма-осмотра (АПО) и экспертиз растягивала сроки досудебных ответов, перегружала команду и повышала риск ошибок: из-за этого клиенты дольше ждали решения по компенсациям, накапливалась очередь и падало качество сервиса.
Агентство-исполнитель кейса

OSMI IT
Будем рады обсудить ваш проект! Связаться с нами проще всего по контактам, указанным на сайте https://osmi-it.ru/

1. Вводная задача от заказчика, проблематика, цели
Цель
Создание корпоративного сервиса, который позволит с помощью ИИ-агентов автоматически распознавать и категоризировать АПО, распознавать экспертизы от клиента, производить автосверку АПО с экспертизой клиента и заводить дефекты в «Техзоре», исходя из данных.
Задачи
- Разработать MVP веб-интерфейс для загрузки документов.
- Разработать веб-интерфейсы для анализа содержания документов и для работы с распознанными данными с возможностью скачивания готовых и отредактированных документов в редактируемом формате.
- Сократить время обработки документа. Уйти от ручной работы к ИИ-агенту для распознавания Word-файлов/сканов, автоклассификации, сравнения, расчёта стоимостей, формирования ведомостей.
- Обеспечить 100% обработку обращений: автоматизировать весь поток и контроль полноты.
- Стандартизировать и структурировать данные о дефектах: передавать в «Техзор» через АРІ, автоматически создавая карточки из распознанных данных.
- Снизить нагрузку на сотрудников и передать рутинные операции ИИ-агенту.
- Ускорить ответы на досудебные обращения, сократить цикл «получение документа → сформирован ответ / SLA».
- Внедрить систему автоматизации в контур системы и развернуть в нём платформу OSMI AI.

2. Описание реализации кейса и творческого пути по поиску оптимального решения
Что сделали
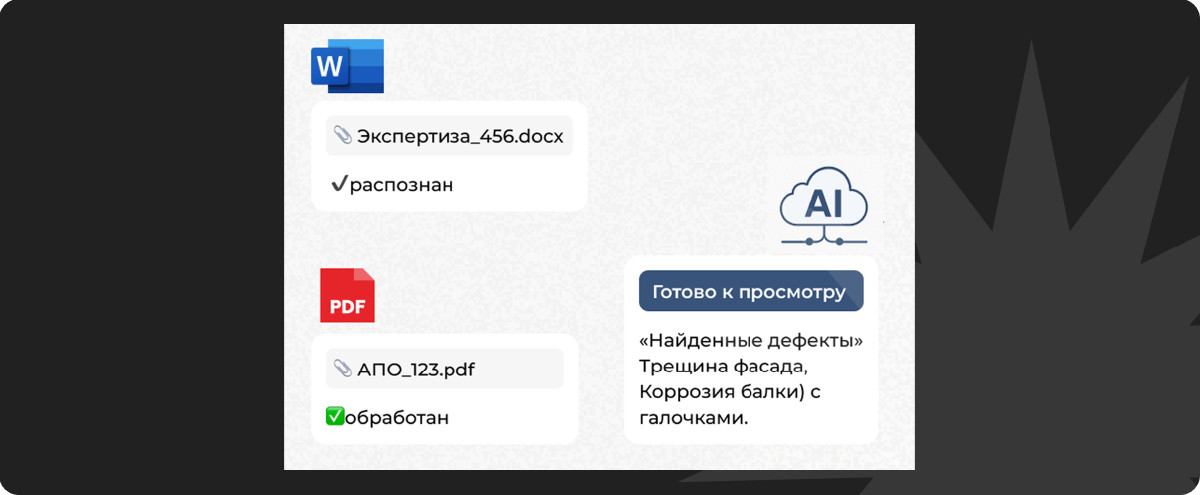
Мы внедрили ИИ-агента, который берёт на себя полный цикл обработки АПО и экспертиз девелопера. Агент распознаёт загруженные документы (Word и сканы), приводит данные к единому формату и автоматически классифицирует дефекты и виды работ по справочникам.
Затем он:
- сопоставляет новые материалы с ранее обработанными, выделяя совпадающие и новые дефекты,
- формирует ведомость,
- рассчитывает стоимость работ.
Результаты в структурированном виде передаются в «Техзор» — внутреннюю систему фиксации дефектов и ведения карточек — где автоматически создаются карточки дефектов. Затем в веб-интерфейсе пользователь видит, из каких фрагментов текста сформированы поля карточки, и проверяет/подтверждает корректность (при необходимости вносит правки).
Этапы проекта
Проект включал 3 релиза MVP общей продолжительностью 3,5 месяца.
Этап 1
Начали с анализа и проектирования и сразу собрали прочный фундамент проекта: согласовали целевую архитектуру и визуализировали её на диаграммах (включая ERD и схемы интеграций), утвердили план по информационной безопасности и развернули каркас инфраструктуры для Dev и Stage.
Параллельно подготовили базу для качества распознавания — собрали эталонный датасет с выверенным балансом АПО и экспертиз и составили стартовые словари дефектов и работ, чтобы метрики дальше считались на одинаковой основе.
На этом основании провели POC на 50 образцах (OCR + LLM/NER), зафиксировали базовые метрики и подняли каркас бэкенда с загрузкой, очередями задач и хранилищем — после чего перешли к ML-разработке.
Сделали работу «сквозной»: пользователь заходит в веб-интерфейс, загружает документы, а система сразу распознаёт данные из АПО и экспертиз. Всё, что нужно поправить или уточнить, редактируется на месте — можно добавлять и удалять дефекты, виды работ, помещения и локализации
Готовый результат выгружается в редактируемые форматы (Excel и Word), а исходники и итоги распознавания надёжно сохраняются в системе, чтобы к ним можно было вернуться и продолжить работу.
Этап 2
На бэкенде мы развернули API для загрузки, надёжное хранилище и очереди задач — чтобы поток документов обрабатывался стабильно и предсказуемо. На этом каркасе собрали ML-пайплайн: OCR, извлечение сущностей (NER) и классификация дефектов/видов работ. Уже на черновой итерации вышли на F1 > 0,82, а результаты проверяются через встроенный модуль сверки.
Чтобы работа была удобной для пользователей, спроектировали UI/UX: подготовили дизайн-систему и прототипы экранов — от загрузки и валидации до сверки и редактирования справочников.
Добавили автоматическую сверку данных между АПО и экспертизами клиента, сформировали документ-сравнение и реализовали его выгрузку.
Для будущей передачи данных во внешние контуры сделали интеграционный адаптер «Техзор» в виде заглушки с формализованными контрактами. Экспорт результатов уже доступен и на этом этапе: реализована первичная выгрузка в Word и Excel.
Этап 3
В третий месяц работ мы завершили функционал: добавили валидацию и редактирование, доработали справочники, реализовали сверку АПО и экспертизы и экспорт ведомостей, вышли на целевые метрики качества на валидации F1 по дефектам и работам выше 0,90, интегрировались с «Техзором» для создания дефектов из системы с целевым SLA API не более 1 секунды на дефект, провели аудит и настроили ретраи, выполнили нагрузочные и проверки безопасности на объёмах порядка 350 документов в месяц и пиках свыше 30 документов в час, а также настроили журналирование.
Реализовали передачу сформированных и подтверждённых пользователем дефектов в «Техзор» через API для автоматического создания карточек и загрузки информации в карточку квартиры.
Финально провели отладку и сдачу: пилотировали решение на реальных данных из ~10 документов, сформировали отчёт по SLA (доступность > 99%) и закрыли инциденты, подготовили руководства пользователя и администратора, регламенты обновления словарей и ML, план on-prem-развёртывания (Helm/Docker, сети, БД) и ввели систему в промышленную эксплуатацию.
Stack
- Платформа OSMI AI
- Загрузка документов: Веб-интерфейс (React/Next.js), Backend (Python FastAPI), загрузка через UI и REST API.
- Распознавание данных: OCR (Tesseract OCR), LLM, классификаторы.
- Валидация данных: Web UI (React + Ant Design), backend-валидация (Pydantic, Python), справочники в Postgres.
- Хранение и загрузка информации: Postgres (реляционные данные), Redis (кэш сессий).
- Анализ и сверка документов: ML-модуль (Python, scikit-learn/PyTorch), алгоритмы LLM (Yandex GPT PRO /
- Qwen 2.5 205B), сравнение JSON структур.
- Формирование документа-ведомости: OSMI AI, Yandex GPT PRO / Qwen 2.5 205B, Pandas + Jinja2 (шаблоны), экспорт в Word/Excel (python-docx, openpyxl).
- Обмен данными с «Техзор»: REST API (FastAPI адаптер), OAuth2/JWT авторизация, очереди (RabbitMQ/Kafka при росте нагрузки).
3. Результаты сотрудничества
Снижение среднего времени рассмотрения и ответа на досудебное обращение
Было — 40 дней
Стало — 12 дней
Увеличение доли обработанных досудебных обращений
Было — 60%
Стало —100%
Время обработки документа 0.90
SLA 99%
Снижение времени анализа и расчета компенсации
4. Заключение
Благодаря сквозной автоматизации время обработки снижается, ручная нагрузка уходит, данные становятся единообразными и пригодными для аналитики, а поток досудебных обращений закрывается полностью.
Агентство-исполнитель кейса
OSMI IT
Будем рады обсудить ваш проект! Связаться с нами проще всего по контактам, указанным на сайте https://osmi-it.ru/