

Авторизация
Сброс пароля
ETL и датавиз для Rusprofile: seo-аналитика на больших данных
Заказчик: Rusprofile

Мы разработали систему ETL и дашбордов для клиента, решив проблему с анализом данных из-за семплирования в Яндекс Метрике. В результате, клиент получает точные данные для SEO-мониторинга и экономит 300 тыс. рублей в месяц, исключив необходимость в Метрике ПРО.
Агентство-исполнитель кейса

JetStyle
20 лет мы делаем всё для решения бизнес-задач клиентов. Занимаемся разработкой цифровых продуктов и сервисов, UX/UI и интернет-маркетингом, а также созданием решений с AR и VR.

1. Вводная задача от заказчика, проблематика, цели
Сложность анализа больших объемов данных для контроля и повышения эффективности поискового продвижения сайта из-за семплирования. Несемплированные данные доступны в интерфейсе Метрики максимум за две недели. Чтобы получить более полный доступ, необходимо подключать Метрику ПРО (от 300 тыс. рублей в месяц).
2. Описание реализации кейса и творческого пути по поиску оптимального решения
ЦЕЛИ ДАШБОРДА
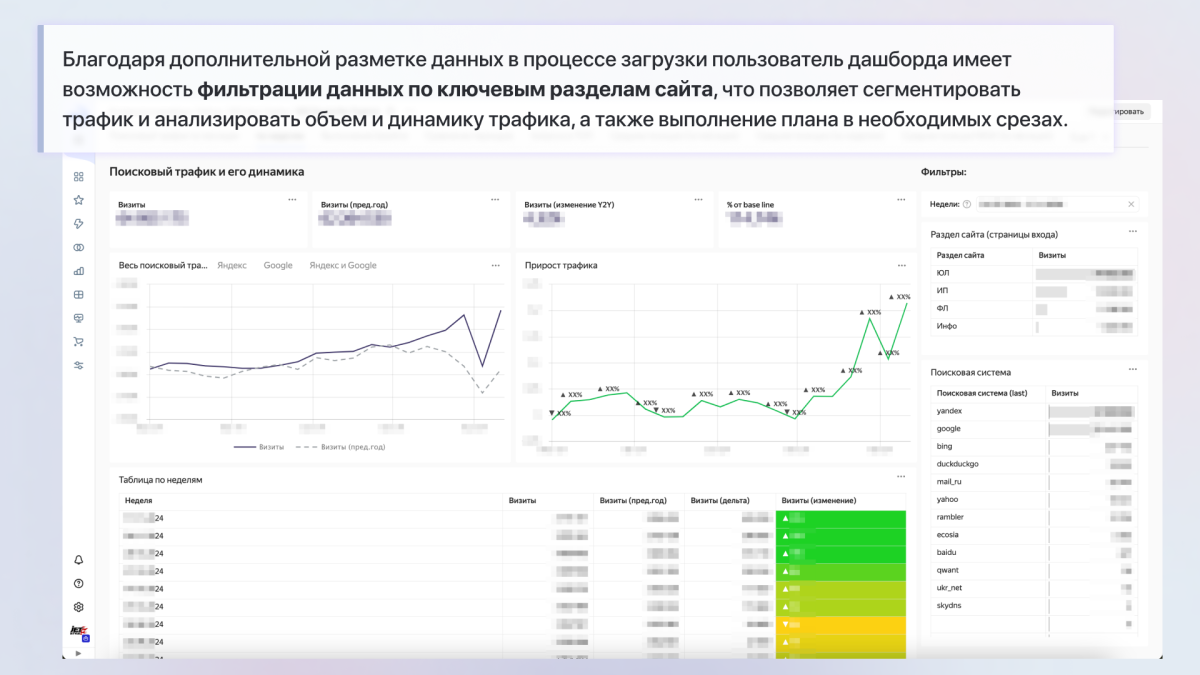
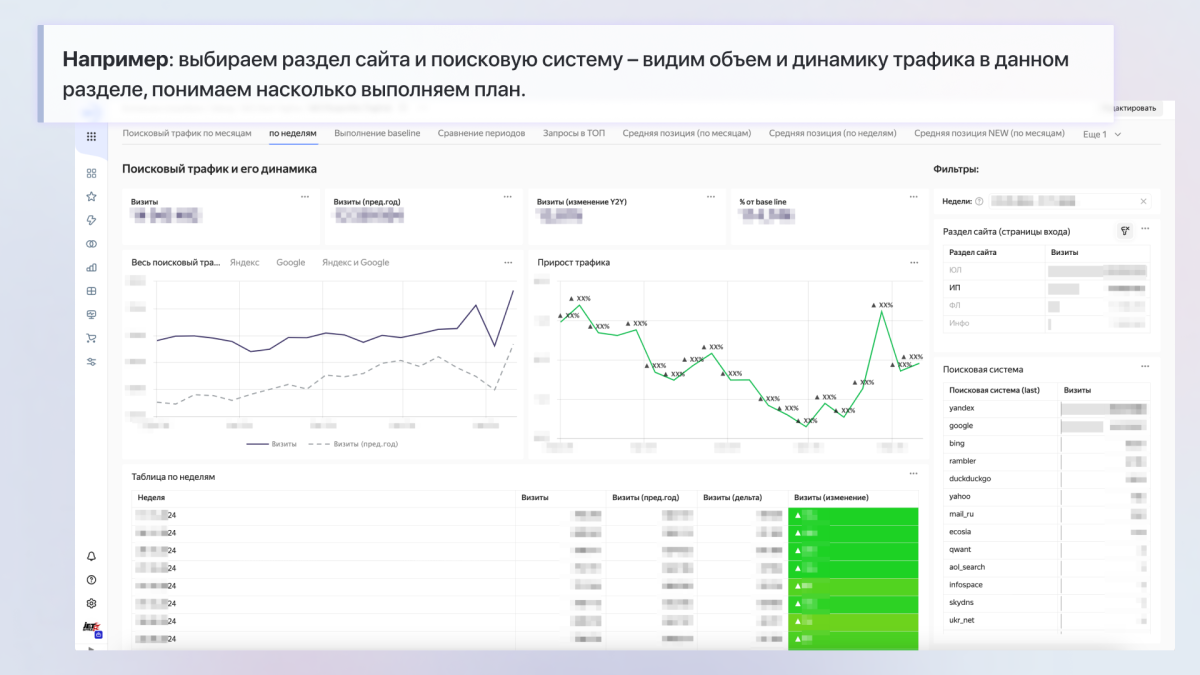
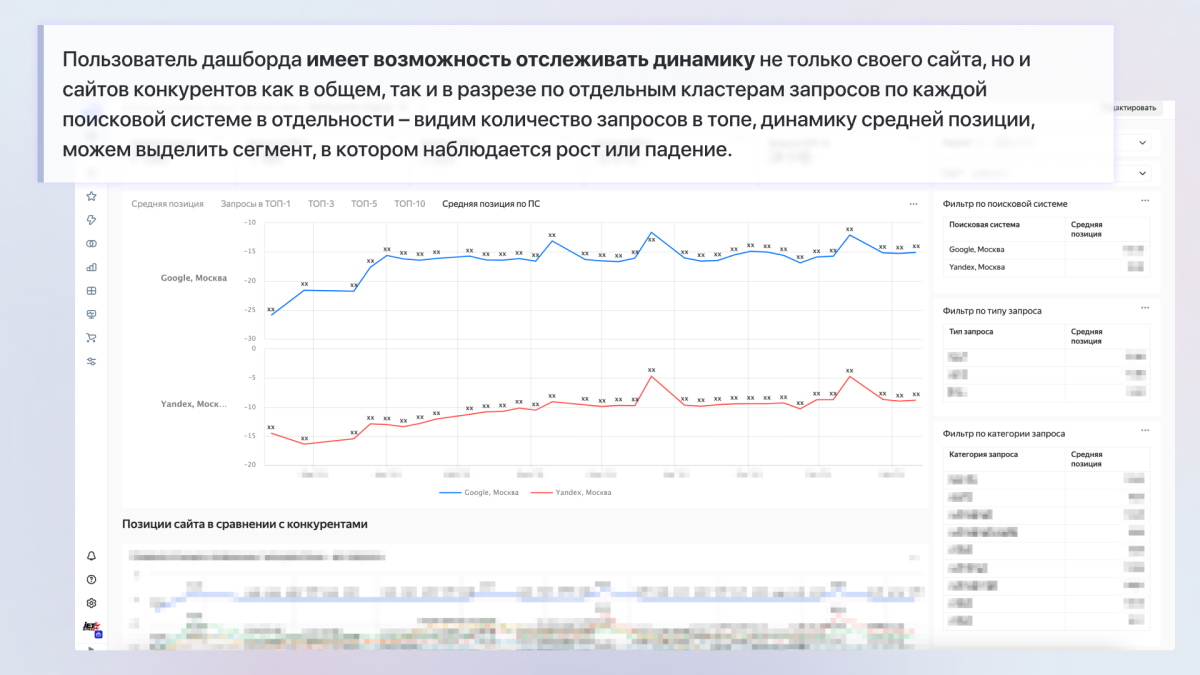
- Мониторинг ключевых метрик SEO: позволяет быстро отслеживать динамику органического трафика и видимость сайта по ключевым показателям (поисковая система, группа запросов, смысл поискового запроса).
- Принятие решений на основе данных: из-за семплирования в Яндекс.Метрике данные часто искажены. Дашборд предоставляет чистые, несемплированные данные для анализа, что упрощает принятие стратегических решений.
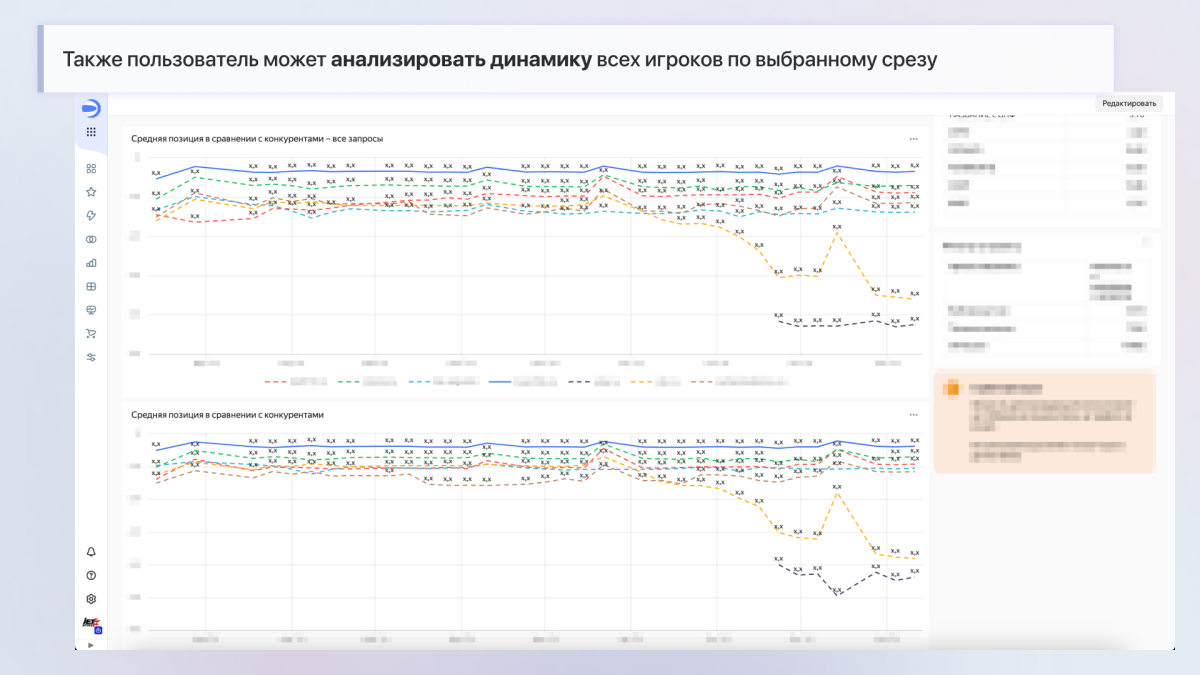
- Идентификация точек роста и проблемных зон: дашборд показывает динамику роста по группам запросов и позволяет оперативно выявлять резкие падения позиций по отдельным группам, что дает возможность своевременно принимать меры.
Основная особенность проекта — действительно большой объем данных.
Например, выгрузка данных из Яндекс.Метрики за один месяц содержит около 15 млн строк и весит более 3 ГБ, и это при использовании всего 14 полей из всех доступных в Logs API (https://yandex.ru/dev/metrika/ru/logs/fields/visits).
Чтобы сохранить доступ к данным, мы использовали только российские и опенсорсные решения:
- ClickHouse — для хранения данных, поскольку эта колоночная СУБД разработана специально для работы с большими объемами данных.
- Airflow — для оркестрации потоков данных.
- Yandex DataLens — для визуализации данных, так как инструмент российский, обладает нужным функционалом и активно развивается.
- Jupyter Notebooks (Python) — для удобства работы с кодом (на основе опыта Netflix: https://netflixtechblog.com/notebook-innovation-591ee3221233, https://netflixtechblog.com/scheduling-notebooks-348e6c14cfd6).
Мы спроектировали структуру датасета и его хранение в базе данных, чтобы:
- не выгружать лишние данные, которые не будут использоваться;
- предусмотреть защиту от дубликации данных при загрузке;
- защитить процесс загрузки данных от сбоев соединения.
Также мы написали коннекторы к:
- Logs API Яндекс Метрики;
- API Топвизора.
Подробная схема представлена в блоке с изображениями.
Для обеспечения безопасности и повышения скорости работы дашборда в базе данных создано несколько слоев:
- временные данные (tmp-слой) — сюда данные загружаются на начальном этапе. В случае обрыва соединения затронуты будут только временные таблицы, а основная таблица останется нетронутой;
- сырые, неагрегированные данные (raw-слой) — сюда данные импортируются из временных таблиц. Дополнительно проверяется отсутствие пересечения датасетов, а дата импорта фиксируется для возможности отслеживания изменений;
- витрины данных (dwh-слой) — этот слой формируется на основе raw-слоя и содержит агрегированные данные в нужных срезах. Использование витрин снижает нагрузку на базу и ускоряет загрузку чартов в дашборде.
Такая структура защищает от ошибок и ускоряет работу дашборда.
При загрузке данных мы дополнительно обогащаем их, чтобы получить дополнительные срезы, недоступные в текущих инструментах:
1. Для данных из Яндекс Метрики
- размечаем разделы сайта с помощью регулярных выражений, что позволяет быстро фильтровать по ключевым разделам в дашборде;
- вычисляем плановые показатели с индивидуальными коэффициентами для каждой поисковой системы, что даёт возможность гибко задавать план по трафику и контролировать его выполнение;
2. для данных из Топвизора – размечаем запросы по группам и поисковому интенту на основе словаря в Google Sheets, что обеспечивает более гибкую сегментацию в отчетах.
Для обеспечения актуальности данных в отчетах мы разработали пайплайн в Apache Airflow:
- данные из Яндекс.Метрики выгружаются ежедневно за предыдущий день и загружаются в базу;
- по понедельникам пересчитывается агрегация данных о визитах из Яндекс.Метрики;
- также по понедельникам выгружаются данные Топвизора за прошедшую неделю и обновляется агрегация;
- по результатам всех операций в Telegram-чат отправляются уведомления о статусе и обновлении выгрузки, а логи хранятся на сервере в формате Jupyter-ноутбуков, что позволяет легко определить причину сбоя в случае возникновения ошибки.
3. Результаты сотрудничества
Мы создали ETL и систему дашбордов, которые решают проблему анализа больших объемов данных для контроля и повышения эффективности поискового продвижения сайта из-за семплирования.
Как проект изменил жизнь пользователей
Наш клиент – Rusprofile – сервис проверки и анализа контрагентов. На портале Rusprofile размещена подробная актуальная информация о более чем 10 миллионах российских юридических лиц и 12 миллионах индивидуальных предпринимателей. Имея более 500 000 визитов в сутки, наш клиент столкнулся с дичайшим семплированием* в Яндекс Метрике, которые не дают посмотреть точные данные более, чем за 2 дня.
Мы создали ETL и систему дашбордов, которые решают эту проблему (для чего на старте обработали более 120 Гб сырых данных из Яндекс Метрики и Топвизора, и в результате исходная таблица в базе данных содержит более 700 млн строк).
На данный момент:
- затраты на настройку системы визуализации окупились еще в августе;
- мы экономим для клиента по 300 000 рублей ежемесячно, исключив необходимость подключения Метрики ПРО для доступа к несемплированным данным;
- за счет собственной системы хранения и обработки данных обеспечиваем постоянный доступ ко всему массиву информации.
*Семплирование — процесс выборки части данных для анализа, применяемый для снижения нагрузки на систему.
Сергей Торкунов
Head of SEO, Rusprofile
Мы долго искали тех, кто сможет нам помочь с разработкой SEO-дашборда и полной автоматизацией процесса обработки и хранения данных. С коллегами из JetStyle познакомились в чате конференции Baltic Digital Days.
В процессе работу у нас сложилась легкая и при этом эффективная коммуникация: ребята всегда были на связи, старались максимально объяснять все детали технической реализации, предлагали варианты архитектурного решения, если выяснялись какие-то нюансы, перепридумывали, как и что лучше сделать. Мы вместе много и усердно дебажили систему. В итоге – довольны результатом и имеем планы на дальнейшее развитие.

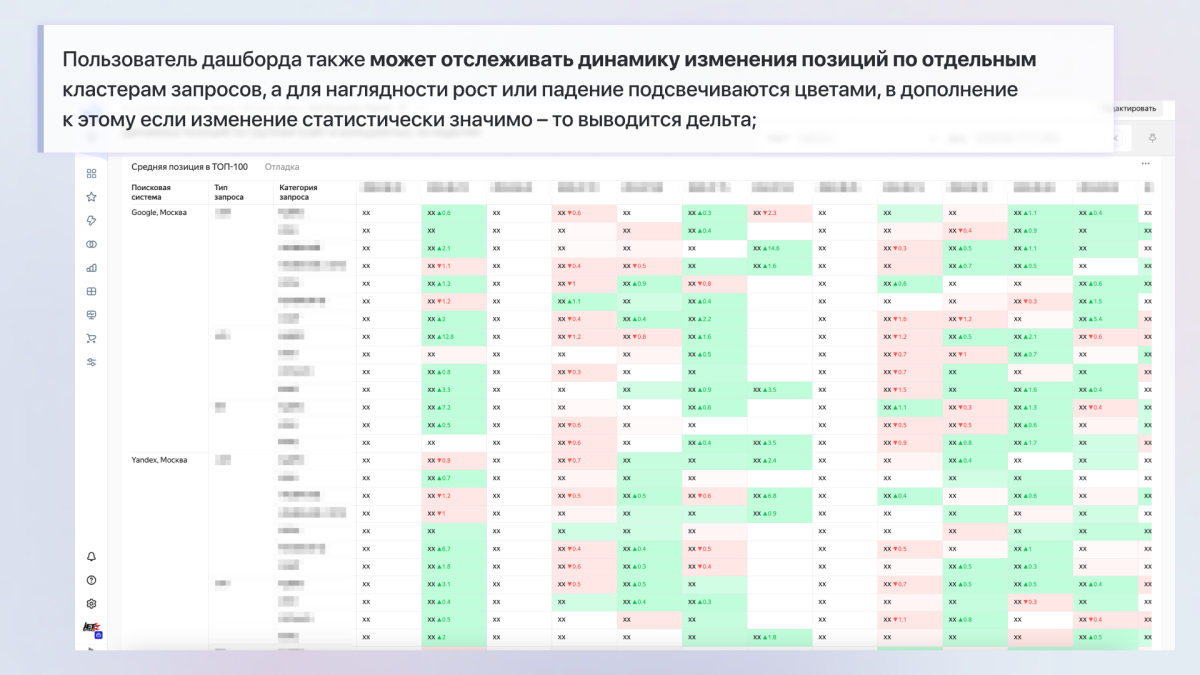
4. Заключение
Инсайты, гипотезы, процесс создания и взаимодействия с заказчиком
Сам дашборд мы создали в Yandex DataLens, следуя продуктовой логике:
- На старте у нас были четкое понимание ожиданий заказчика, примерное представление о конечном результате и важные для него срезы данных.
- Настроив выгрузку данных из Яндекс.Метрики, мы сразу реализовали MVP вкладки с данными о посещаемости. После этого в ходе 3–4 итераций мы доработали дашборд: изменили логику расчета план-факта, внедрили витрины для повышения скорости, добавили сравнение произвольных периодов.
- К моменту работы над вкладкой с позициями заказчик уже получил рабочий инструмент для отслеживания динамики поискового трафика. В процессе разработки вкладка с позициями также претерпела ряд изменений и улучшений.
- После создания каждой вкладки мы проводили кросс-проверку данных, чтобы исключить ошибки в расчетах.
- В процессе настройки дашборда у нас возникали интересные заморочки, например:
Раздел «план-факт». Сначала он рассчитывался отдельно по месяцам и неделям на уровне DataLens и общей формулы. Позже стало понятно, что нужны разные коэффициенты для Яндекса и Google. Поэтому расчеты были перенесены на уровень базы данных, что упростило контроль и повысило скорость загрузки чартов.
Позиции в Топвизоре. Мы обнаружили, что из-за недостаточного баланса позиции могут не обновиться. На этот случай добавили возможность задавать позиции по шаблону для конкретного дня и среза в Google Sheets — эти данные подхватываются при агрегации и записываются в таблицу.
Загрузка датасета с историческими данными из Яндекс.Метрики. Для этой задачи потребовался стационарный ПК, так как на MacBook не хватило места на SSD-диске. Мы написали цикл, который целую ночью загружал данные в базу небольшими частями по 1 млн строк.
Неожиданные вопросы. Как-то раз Сергей Торкунов (наш заказчик) спросил, например, такое: «Сколько страниц нужно взять из 36 млн, чтобы выборка отражала положение дел с точностью 95%?». Нам периодически приходилось освежать знания по теории вероятностей, а однажды даже обратиться к преподавателю из университета, чтобы убедиться в правильности расчетов. Работать с человеком, который входит в топ-20 известнейших SEO-персон, не только ответственно и круто, но и очень увлекательно!
Развитие дашборда. Пока писали этот кейс, доработали датасет по позициям на основе новых вводных. Теперь в мониторинге еженедельные данные по 515 000 поисковых запросов, которые можно отфильтровать и по сайту заказчика, и по конкурентам. При этом у всех будет разбивка по группам и смысловому интенту.
Агентство-исполнитель кейса
JetStyle
20 лет мы делаем всё для решения бизнес-задач клиентов. Занимаемся разработкой цифровых продуктов и сервисов, UX/UI и интернет-маркетингом, а также созданием решений с AR и VR.