
Авторизация
Сброс пароля
Кейс Литрес: снимаем ограничения Google Analytics и разрабатываем собственную систему сквозной аналитики
Заказчик: Литрес
Страница кейса/результат: https://medianation.ru/cases/keys-litres-skvoznaya-analitika/

Google Analytics позволяет отслеживать только 10 млн обращений в месяц, что ничтожно мало для такой крупной компании, как Литрес. Команда агентства MediaNation и маркетологов Литрес настроили систему сквозной аналитики на базе собственной разработки StreamMyData.
Агентство-исполнитель кейса

MediaNation
Агентство MediaNation основано в 2008 году и оказывает комплексные услуги продвижения бизнеса в интернете. Среди клиентов MediaNation такие бренды, как Адамас, Линзмастер, Butik.ru, ЛитРес, Читай-Город, MyToys, Amediateka, Hansa, Wall Street English, Gett и другие.

1. Вводная задача от заказчика, проблематика, цели
Исходная ситуация
Пандемия 2020 года стала еще большим бустером для развития бизнеса Литрес: число обращений на сайт и в мобильные приложения существенно выросло, что повлекло за собой и рост данных. Возможности Google Analytics постепенно исчерпали себя — количество обращений, которые позволяет отслеживать система, стало превышать 10 млн в месяц. Платная версия GA с большей пропускной способностью обходилась бы более 100-120 000 USD в год. Такие расходы выглядели нецелесообразными, и переход на нее не рассматривался. Кроме того, Google Analytics мог предложить только сбор данных по сайту, тогда как у Литрес развита еще и целая экосистема мобильных приложений.
Задача
Перед командой MediaNation и Литрес встала задача создания альтернативной аналитической платформы, которая позволяла бы собирать огромный объем данных из собственных каналов коммуникаций с клиентами и рекламных систем, а далее объединять их для дальнейшего маркетингового анализа.
Для крупного коммерческого проекта это были первоочередные задачи, потому что наличие кастомной системы сквозной аналитики позволяет более эффективно управлять рекламой, персонализировать акции и предложения. Потенциально это ведет к снижению расходов на рекламу и увеличению конверсий.

2. Описание реализации кейса и творческого пути по поиску оптимального решения
Работа состояла из следующих этапов:
- Сбор данных и визуализация объединения потоков
- Проблемы с созданием потоков и передачей данных в Appsflyer
- Проблемы с переносом данных в BigQuery
- Обработка 5 миллионов хитов и сбор сессий
- Обновление и синхронизация таблиц
- Отслеживание кросс-платформенного пути пользователя
- Настройка UTM-разметки
Далее подробно расскажем про каждый из них.
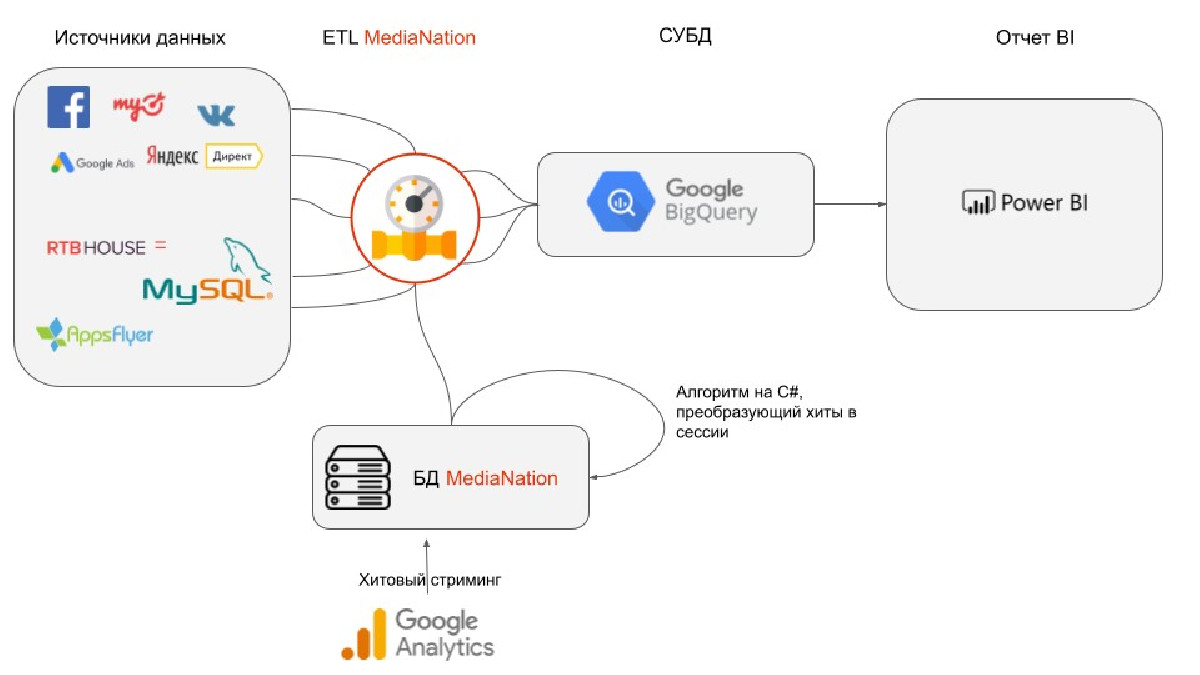
1. Сбор данных и визуализация объединения потоков
Прежде всего нам нужно было собрать данные из всех рекламных систем. Потоков по передаче и сбору данных было множество, а именно:
Google Ads;
Яндекс.Директ;
Facebook;
VK;
MyTarget;
Google Analytics;
Appsflyer;
MySQL;
RTBHouse;
Criteo;
Firebase;
и т.д.
Нам также нужно было собрать данные из мобильных приложений клиента: два приложения Литрес Читай (Andriod и iOS) и два приложения Литрес Слушай (Andriod и iOS) и связать их с данными из CRM-системы.
Всю систему потоков данных, которую мы хотели реализовать, можно представить в виде следующих шагов:
- Импортируем данные по расходам из рекламных кабинетов Литрес (Facebook, Google Ads, RTB House, MyTarget, VK, Я.Директ), а также данные по купленным товарам и доходам с них из товарной базы данных (MySQL) с помощью разработанных нами коннекторов в Google BigQuery;
- Одновременно с импортом данных мы выгружаем хиты, которые собираются в сессии и также попадают в BigQuery;
- Склеиваем эти данные между собой по общим ключам с помощью специального SQL-запроса, написанного в BigQuery. В результате мы получаем сессии пользователя с его кросс-платформенными переходами, стоимостью его привлечения и доходом с транзакций;
- Визуализируем итоговые данные с помощью графических инструментов в Google Data Studio.
Однако не все было гладко. В ходе работ мы столкнулись с рядом проблем и челленджами с передачей и переносом данных.
2. Проблемы с созданием потоков и передачей данных в Appsflyer
Выгружать данные из систем оказалось непросто. Мы столкнулись с рядом проблем при создании потоков и на этапе передачи данных из Appsflyer в BigQuery:
- Appsflyer ограничивает количество вызовов к своему API. Поэтому первая выгрузка заняла большое количество времени. А вот ежедневно обновлять данные, добавляя только новые к уже имеющимся, оказалось гораздо проще;
- Appsflyer позволяет импортировать за раз не более 200 тысяч строк в базу данных. Поэтому наполнение таблиц данными мобильной аналитики заняло много времени и усилий.
3. Проблемы с переносом данных в BigQuery
Не только сервисы мобильной аналитики могут мешать быстрому сбору данных. Так мы столкнулись с трудностями при объединении данных с разных серверов в BigQuery. Данные из системы Firebase хранились на американском сервере, а сам проект с таблицами — на европейском. Чтобы обойти ограничения BigQuery при переносе данных, нам потребовалось сделать выгрузку Firebase в наше собственное представление в BQ, и только после этого загрузить их в представление Литрес.
Работа была осложнена тем, что нам не удалось найти четкую инструкцию по неймингу таблиц у Google, и в итоге мы использовали недопустимые символы в названии таблиц. Это не позволило нам проделывать операции с таблицами через API BigQuery. Нам пришлось подключить платную техподдержку Google, чтобы решить проблему. И только через несколько месяцев мы смогли реализовать начатое.
4. Обработка 5 миллионов хитов и сбор сессий
Для получения данных веб-сессий по пользователям мы разработали уникальный алгоритм, который преобразовывает данные хитов из Google Analytics в сессии с учетом идентификаторов пользователя. Для билдинга сессий мы:
- Выгрузили хитовые данные из Google Analytics в промежуточную базу данных;
- Отработали алгоритм, который преобразует хитовые данные в сессионные с учетом идентификаторов пользователя userID, clientID пользователя и даты и времени, когда он был онлайн;
- Выгрузили созданные сессии в СУБД BQ (система управления базой данных BigQuery), где находятся данные из остальных источников.
Ежедневно мы обрабатываем около пяти миллионов хитов весом около 4 ГБ. Чтобы ускорить процесс билдинга сессий, мы разделили пользователей на равные группы, создали очередь и запустили несколько потоков для одновременной обработки хитов. Это позволило нам значительно увеличить скорость обработки и уменьшить требовательность к ресурсам, особенно к оперативной памяти.
Appsflyer также предоставляет готовые сессионные данные по пользователям для отслеживания активности на мобильных устройствах. Поэтому дополнительных операций с ними не требовалось.
5. Обновление и синхронизация таблиц
Еще одним важным аспектом работы над проектом являлась корректная настройка расписания обновления таблиц с данными. Мы обнаружили, что коллеги из Литрес не всегда видели актуальные данные за предыдущий день. Мы начали разбираться и заметили, что обновление большинства таблиц запланировано на начало календарного дня, в то время как хиты билдятся в сессии всю ночь и только к 7 утра попадают к нам в BQ. Поэтому мы перенесли время обновления датасетов на раннее утро с соблюдением последовательности обновления одной таблицы за другой.
Так, мы дали сначала выгрузиться сессиям и затем подтягивали к ним данные из рекламных кабинетов и СУБД товаров Литрес. После этих обновлений скрипты формировали кросс-платформенный отчет из полученных данных.
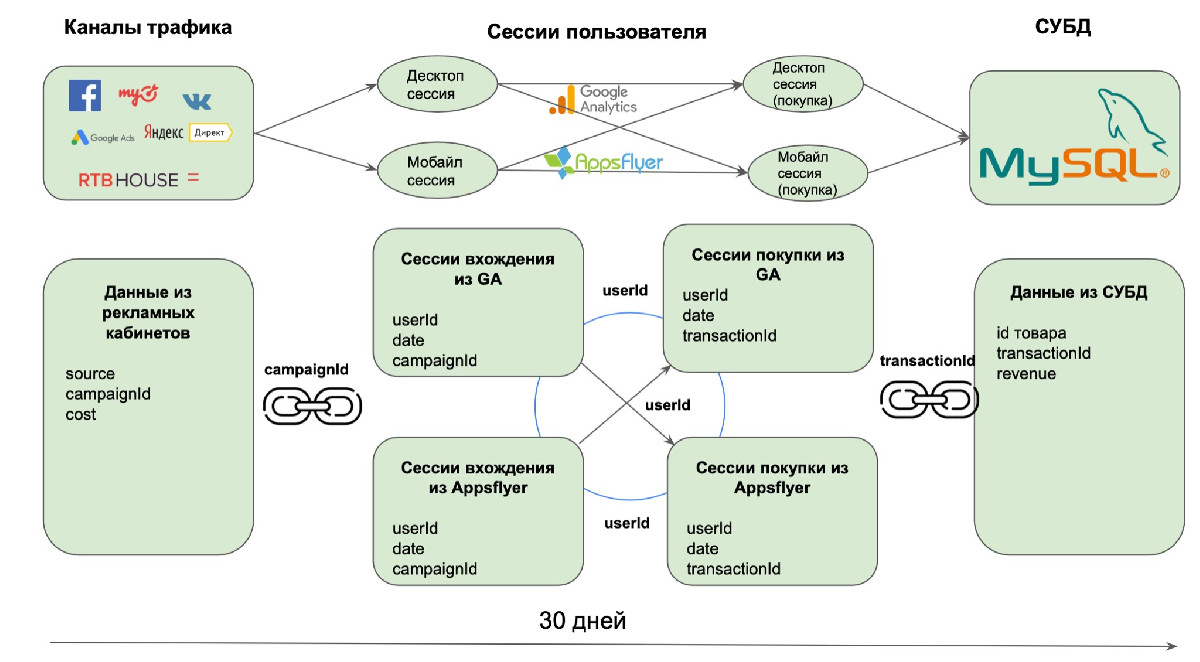
6. Отслеживание кросс-платформенного пути пользователя
Когда данные из всех систем были собраны в одном месте, мы смогли приступить к отслеживанию пути пользователя в его кросс-платформенных взаимодействиях с момента перехода на сайт или приложение до покупки. Это помогло нам посчитать реальную стоимость привлечения клиента и доход с каждого пользователя вне зависимости от того, сделал ли он покупку на компьютере или мобильном устройстве.
У нас были идентификаторы пользователя userID и clientID, а также дата и время сессий. Поэтому мы смогли отследить все десктопные и мобильные сессии пользователя и расположить их в хронологическом порядке.
Сегмент, представляющий наибольший интерес, состоял из пользователей, которые попали на сайт/приложение с десктопа или мобильного устройства, но купили товар на другом устройстве. Мы написали специальный SQL-запрос — код на языке SQL, совершающий операции над данными в базе данных. Он не только идентифицировал таких покупателей, но и определял их входную сессию и сессию с транзакцией, между которыми прошло не более 30 дней. Если транзакция произошла спустя большее количество времени, то ее было бы некорректно связывать с источником трафика, из которого пришел пользователь.
Для полученного кросс-платформенного сегмента мы объединили сессионные данные с данными их рекламных кабинетов по параметру “campaignId” и затем смогли посчитать расходы на привлечение таких пользователей. А также доходы по их покупкам, которые мы взяли из товарной базы данных Литрес, предварительно соединив их с сессиями по полю “transactionId”. Таким образом, мы не только смогли посчитать рентабельность рекламы по источникам и кампаниям, но и определить ее на уровне сессий.
7. Работа над UTM-разметкой
Полученного результата невозможно было бы достичь без создания единого стандарта UTM-разметки данных. Если мы не следовали заранее установленному стандарту и неверно прописали UTM-метки для рекламных кампаний, то не смогли бы корректно атрибуцировать стоимость пользовательских сессий и посчитать рентабельность рекламных кампаний.
Дело в том, что Google Analytics по умолчанию видит названия и идентификаторы только рекламных кампаний в Google Ads. Считывать другие кампании можно только через парсинг UTM-метки, которая зашита в специальном поле “ga_adContent”.
Чтобы вытащить из меток идентификатор и название кампании, нужно использовать функцию поиска регулярных выражений (regex) на языке SQL. Суть этой функции в том, что мы даем системе шаблон, в соответствии с которым парсится название кампании и другие параметры. Зная, в каком месте UTM-метки содержится название кампании, мы можем поручить системе возвращать текст, который идет после символа “/” и до символа “|”. Но если UTM-метка не соответствует единому шаблону, то функция regex не сработает, как нам нужно.
Поэтому мы предложили клиенту собственное решение UTM-разметки для кампаний в виде шаблона, который мы используем для всех рекламных кампаний в Google Ads:
{lpurl}?utm_medium=cpc&utm_source=google&utm_campaign=НАЗВАНИЕ КАМПАНИИ|{campaignid}&utm_term={keyword}&utm_content={campaign_id}{gbid}{banner_id}{phrase_id}{source}{source_type}{campaign_type}{addphrases}{device_type}{position_type}{region_id}
Для разметки Я.Директ подошел шаблон сервиса “К50”:
?utm_medium=cpc&utm_source=yandex&utm_campaign=название|{campaign_id}&utm_term={keyword}&utm_content=k50id|01000000{phrase_id}{retargeting_id}|cid|{campaign_id}|gid|{gbid}|aid|{ad_id}|adp|{addphrases}|pos|{position_type}{position}|src|{source_type}{source}|dvc|{device_type}|main&k50id=01000000{phrase_id}_{retargeting_id}
Наш отдел рекламы в соцсетях разработал шаблоны меток для основных рекламных кабинетов. Эти решения мы и использовали в данном проекте.
MyTarget:
utm_source=mytarget&utm_medium=cpc&utm_campaign={{campaign_name}}|{{campaign_id}}&utm_content=aid|{{banner_id}}&utm_term=geo|{{geo}}|gender|{{gender}}|age|{{age}}|impression_weekday|{{impression_weekday}}|impression_hour|{{impression_hour}}|user_timezone|{{user_timezone}}
VK:
utm_source=vk&utm_medium=cpc&utm_campaign={campaign_name}_{campaign_id}&utm_content=aid_{ad_id}&utm_product={product_id}
Facebook:
utm_source=facebook&utm_medium=cpc&utm_campaign={{campaign.name}}|{{campaign.id}}&utm_content=cid|{{campaign.id}}|gid|{{adset.id}}|aid|{{ad.id}}|placement|{{placement}}&utm_term=adset_name|{{adset.name}}
Instagram:
utm_source=instagram&utm_medium=cpc&utm_campaign={{campaign.name}}|{{campaign.id}}&utm_content=cid|{{campaign.id}}|gid|{{adset.id}}|aid|{{ad.id}}|placement|{{placement}}&utm_term=adset_name|{{adset.name}}
Используя эти шаблоны UTM-меток для разметки кампаний, мы сделали важный шаг навстречу корректности и полноты рекламных данных, а также их правильному объединению с данными из других систем.
3. Результаты сотрудничества
Нам пришлось очень многое изменить в нашей системе сквозной аналитики StreamMyData для обслуживания такого массива информации. Результатом нашей работы стало создание уникальной платформы.
Теперь у Литрес есть четкое понимание того, как каждый пользователь взаимодействует со всей инфраструктурой технологий и сколько денег необходимо потратить для привлечения того или иного клиента, вплоть до расчета рентабельности на каждого конкретного пользователя.
Полученный результат не только помог учесть “переходящих” пользователей в расчете рентабельности рекламы, но и снабдить нас большим количеством информации о них, которая может быть полезна в прогнозировании вероятности совершения ими покупок.
Эти данные можно использовать в качестве признаков для предиктивной модели. Такие показатели, как количество кликов, просмотры товаров, общее время, проведенное на сайте и в приложении, вносят большой вклад в предсказание вероятности конверсии пользователя. Нам уже удалось добиться точности предсказания совершения покупки пользователем с вероятностью 73%, и это только начало нашего долгого пути. Но об этом мы напишем в следующем кейсе.
"Спасибо нашим партнерам из MediaNation, что не побоялись принять вызов по реализации такой сложной аналитики. Мы действительно столкнулись с рядом ограничений стандартных систем. Объединив все под одной крышей и сделав кросс-канальную кросс-платформенную аналитику, мы можем совершенно по-новому оценивать эффективность рекламных каналов и находить точки роста. И впереди еще очень много задач, доработок и усовершенствовании", — Каландаев Алексей, директор департамента цифрового маркетинга и B2C-продаж, ГК Литрес.
Планы
В наших ближайших планах выделение команды специалистов по Data Science, которые разработают систему предсказания вероятности покупки каждого посетителя сайта с высокой точностью и минимумом затрат на вычисления, а также выстроить систему предсказания LTV каждого клиента и запустить эконометрическое моделирование.
"Сотрудничество с Литрес по данному проекта еще далеко от завершения. Впереди нас ждет долгий путь, который мы хотим пройти рука об руку и создать для клиента не только предиктивные модели, но и отстроить эконометрическое моделирование для развития маркетинга в РФ и в ряде регионов ЕС, в которых сейчас идет активная экспансия. Сотрудничество подтолкнуло нас к тому, что к концу следующего года, мы бы хотели реализовать часть технологий, которые были нами разработаны в рамках данного проекта для рынка в виде SaaS решения", — Барченков Иван, партнер агентства MediaNation.
4. Заключение
Работа с подобным объемом данных принципиально отличается от большинства клиентов, которым не нужно обрабатывать миллиарды строк записей ежедневно. Мы существенно изменили наш подход к построению инфраструктуры работы StreamMyData.ru и теперь можем решать подобные задачи для любого клиента, у которого стоит задача построить систему сквозной аналитики. Ведь теперь мы можем загружать абсолютно любые данные клиента и строить на них различные предсказательные модели.
Агентство-исполнитель кейса
MediaNation
Агентство MediaNation основано в 2008 году и оказывает комплексные услуги продвижения бизнеса в интернете. Среди клиентов MediaNation такие бренды, как Адамас, Линзмастер, Butik.ru, ЛитРес, Читай-Город, MyToys, Amediateka, Hansa, Wall Street English, Gett и другие.