
Авторизация
Сброс пароля

Серверная оптимизация highload-проекта: интернет-магазин из ТОП-100 российского ecommerce и лидер среди интернет-магазинов мебели.
Агентство-исполнитель кейса

Интаро
Интаро разрабатывает интернет-магазины и веб-проекты под заказ, занимается сложной веб-интеграцией и автоматизацией. Разработка осуществляется или с использованием широко известной CMS "1С-Битрикс", или на основе фреймворка Symfony в зависимости от особенностей проекта. Ведется поддержка проектов на фреймворке yii. Некоторые наши проекты: Столплит, Связной, retailCRM, портал Государственной Думы.

1. Вводная задача от заказчика, проблематика, цели
Насколько все плохо?
Для ответа на этот вопрос в “цифрах” нужно провести аудит. Критичными показателями для нас на первом этапе аудита являются время генерации страницы на сервере и время рендеринга (отображения) в браузере. Хорошим суммарным показателем является время менее 1 секунды. Для простого аудита показателем “насколько все плохо” является суммарное время отображения страницы, поделенное на 1 секунду.
Ниже приведен график Яндекс.Метрики, по которому видно, что у ресурса есть проблемы с производительностью. Время полного получения страницы может достигать 9 секунд. Есть большая вероятность, что пользователь не дождется открытия этой страницы и уйдет.
Еще одним немало важным показателем является запас производительности, который можно получить, проведя нагрузочное тестирование на работающем проекте. Нужно иметь в виду, что целью нагрузочного тестирования является получение значения максимальной производительности, т.е. значений, при которых мы получим отказ в обслуживании. Именно поэтому нагрузочное тестирование нужно производить с особой аккуратностью, чтобы не допустить реального отказа в обслуживании. Обычно показателем нагрузочного тестирования является RPS (Requests per second) - количество запросов в секунду, которые способен обработать ваш сервер. Полученный показатель можно сравнить с текущим средним количеством запросов в секунду и получить доступный запас производительности вашего проекта.
Ниже приведен пример нагрузочного тестирования Яндекс.Танком. Тестирование проводилось на «боевом» проекте в час-пик. Видно, что RPS достигал значений близких к 30. Но фактический отказ в обслуживании начался с 17 RPS. Если принять во внимание среднюю нагрузку на сайт около 100 RPS, то можно считать этот запас критически низким, а сервис потенциальной жертвой DDoS (атака, целью которой является отказ в обслуживании).
Кто виноват?
Обычно к таким последствиям приводит отсутствие или ошибки проектирования серверной архитектуры или несогласованность работы разработчиков и системных администраторов. Как правило, над одним проектом могут работать разные команды разработчиков и даже системных администраторов. Но бывает и так, что проект заведомо разрабатывался под низкую нагрузку и к ее резкому скачку оказался просто не готов.
Что делать?
В любом случаем никогда не поздно привести все в порядок. И хочу отметить, что как приведение к хаосу, так и установление порядка в проекте - это слаженный труд разработчиков, системных администраторов, контент-менеджеров и других специалистов. Именно поэтому нужно выделить узкие места проекта, разделить зоны ответственности и комплексно решать проблемы.
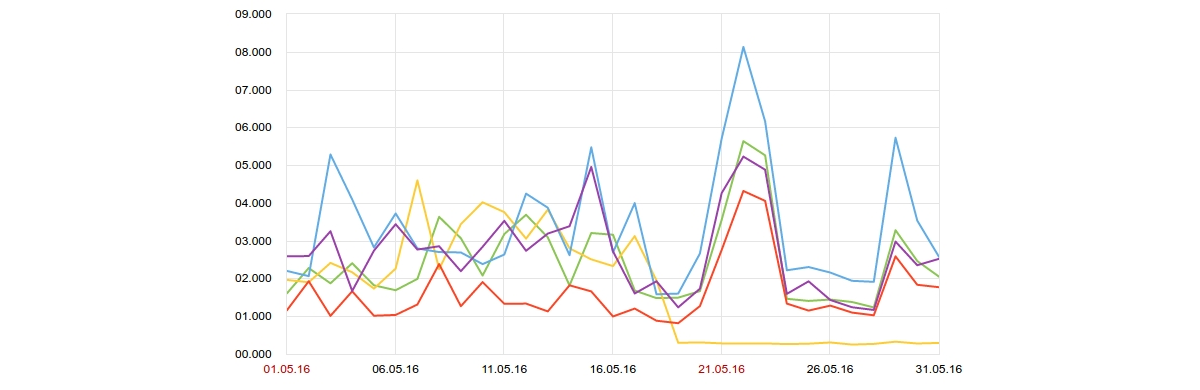
График времени загрузки страниц
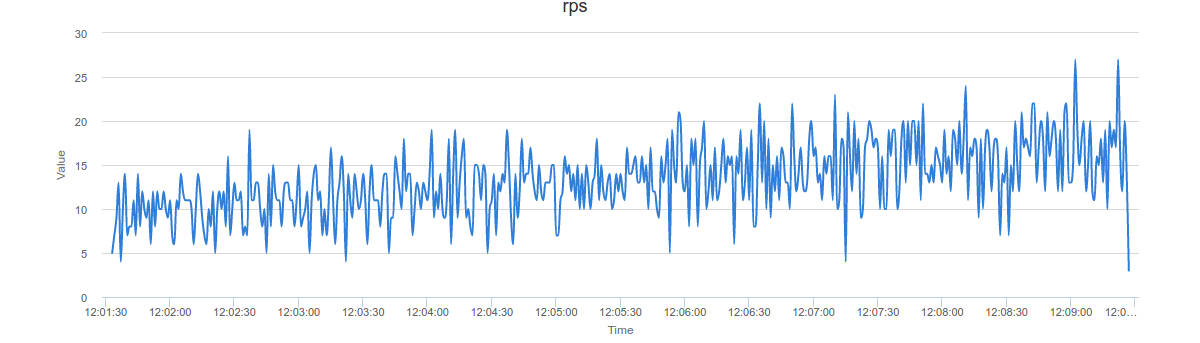
График нагрузочного тестирования
2. Описание реализации кейса и творческого пути по поиску оптимального решения
Серверы - наше все!
Существует поверье, что если купить сервер и он будет достаточно мощный, то можно перестать волноваться и забыть про апгрейд на ближайшие пару лет. Возможно это и верно для проектов со средней посещаемостью, не планирующих прироста пользователей на ближайшее время. Ведь на первый взгляд удобно оплачивать и администрировать один сервер. Но для проектов с высокой посещаемостью, с ее возможными всплесками это в корне не так.
Критически важным для таких проектов является время простоя во время технических работ и сведение к минимуму времени восстановления в случае аварии. Здесь применимо выражение “время - деньги”. Именно поэтому нужно создать такую архитектуру, которая обеспечит нужный уровень отказоустойчивости и масштабируемости.
Три кита правильной конфигурации:
- масштабируемость;
- отказоустойчивость;
- безопасность.
Рассмотрим подробнее.
Масштабируемость
Под масштабируемостью я подразумеваю способность быстро и просто добавлять вычислительные мощности в проект. Именно по этой причине нужно разделить серверы на выполняемые роли. Нужно четко понимать, что много “маленьких” серверов лучше, чем один “большой”. Все серверы одной роли должны быть идентичной конфигурации. Это дает нам возможности для простого горизонтального масштабирования. В случае отказа одного "маленького" сервера мы имеем пропорциональную просадку производительности. В случае отказа одного "большого" мы скорее всего имеем отказ в обслуживании.
Если рассматривать типовой веб-сайт на PHP и СУБД MySQL, то разделение на роли примерно такое: балансировщик запросов, сервер приложения, сервер баз данных.
Балансировщик - сервер с Nginx на борту. Занимается балансировкой запросов к серверам приложений (см. ниже), обработкой и кэшированием статики (картинки, стили, javascript и т.д.), реврайтами. Может выполнять регулярные “тяжелые” задачи по cron.
Сервер приложения – сервер, на котором выполняется бизнес-логика проекта. В нашем случае это код PHP.
На сервере такой роли лучше использовать php-fpm вместо Apache, если нет прямых противопоказаний. Все-таки хороший веб-сервер у нас уже есть. Nginx очень хорошо справляется со своими обязанностями. Главная причина, по которой системные администраторы не спешат отказываться от Apache в качестве бекэнда на “живых” проектах - это наличие файлов .htaccess и, соответственно, куча реврайтов в них. Настоятельно рекомендуем потратить время и переписать все реврайты под Nginx. Он делает это гораздо быстрее по своей природе.
Как уже само собой разумеющееся на сервере, выполняющем бизнес-логику должно быть много кэша. Кэшировать нужно все, что можно. У PHP должен быть OPcache или аналог. Использование memcaсhe в проекте всегда приветствуется.
Синхронизировать файлы проекта между серверами приложений можно любым удобным способом. Например lsyncd.
Забегу вперед и скажу, что на серверах приложений обязательно должен быть реализован функционал распределения нагрузки на БД.
Сервер баз данных - сервер с СУБД MySQL на борту.
Рекомендуем отказаться от использования чистой MySQL и посмотреть в сторону форков, таких как Mariadb и Percona. Для придания отказоустойчивости БД предлагаем посмотреть в сторону кластеризации. У чистой MySQL есть встроенный механизм реализации master-slave репликации. По сути, с его помощью можно реализовать master-master репликацию. Но советовать этого я не буду. Вместо этого предлагаем рассмотреть решение от Percona под названием percona xtradb cluster. Оно реализует настоящую master-master репликацию и полноценный кластер. К тому же он очень прост в управлении, масштабировании и восстановлении в случае сбоя, оснащен встроенным движком xtradb, полностью совместимым с InnoDB. К тому же есть возможность делать резервные копии, которые быстро восстанавливаются, что гораздо быстрее обычного восстановления из sql дампа. А ребята из Mariadb разработали прекрасную утилиту maxscale для распределения нагрузки между серверами.
Отказоустойчивость
Главное правило отказоустойчивости - не допускать наличия единой точки отказа. Т.е. не допускать наличия недублированных узлов. Таким образом, серверов каждой роли у нас должно быть как минимум два. Что касается сервера-балансировщика, то его можно собрать в отказоустойчивый кластер или реализовать Round-robin DNS между несколькими балансировщиками.
По сути, реализуя схему с возможностью горизонтального масштабирования, представленную выше, мы получаем определенный уровень отказоустойчивости. Повышение уровня отказоустойчивости достигается дальнейшим горизонтальным масштабированием, добавляя сервера в нужную роль.
Безопасность
Безопасности много не бывает! Хочу остановиться на базовых моментах:
- 1. Исключить парольный доступ по SSH/SFTP. Насколько стойким бы ни был ваш пароль, хороший бот-нет обязательно его подберет. Самый удобный, на мой взгляд, способ авторизации - это RSA сертификаты. Просто и удобно.
- 2. WAF (Web Application Firewall) - незаменимый инструмент на защите вашего сервиса от XSS и SQL - инъекций. При правильной настройке поможет сэкономить много времени и душевных сил.
- 3. На каждом из серверов обязательно должен быть настроен Firewall с политикой по умолчанию “Запрещено”. Наружу должны быть открыты только необходимые порты.
Для защиты от DDoS атак существует масса способов. Она может осуществляться на уровне хостинга. Некоторые маршрутизаторы обладают возможностью интеллектуальной обработки трафика и очистки его от “мусора”. Обычно такая услуга предоставляется провайдерами на платной основе. Тюнинг ядра Linux может помочь устоять перед другими видами сетевых атак.
Илья Безрукавников
Системный администратор, Intaro
Нужно четко понимать, что много “маленьких” серверов лучше, чем один “большой”. Все серверы одной роли должны быть идентичной конфигурации. Это дает нам возможности для простого горизонтального масштабирования. В случае отказа одного "маленького" сервера мы имеем пропорциональную просадку производительности. В случае отказа одного "большого" мы скорее всего имеем отказ в обслуживании.

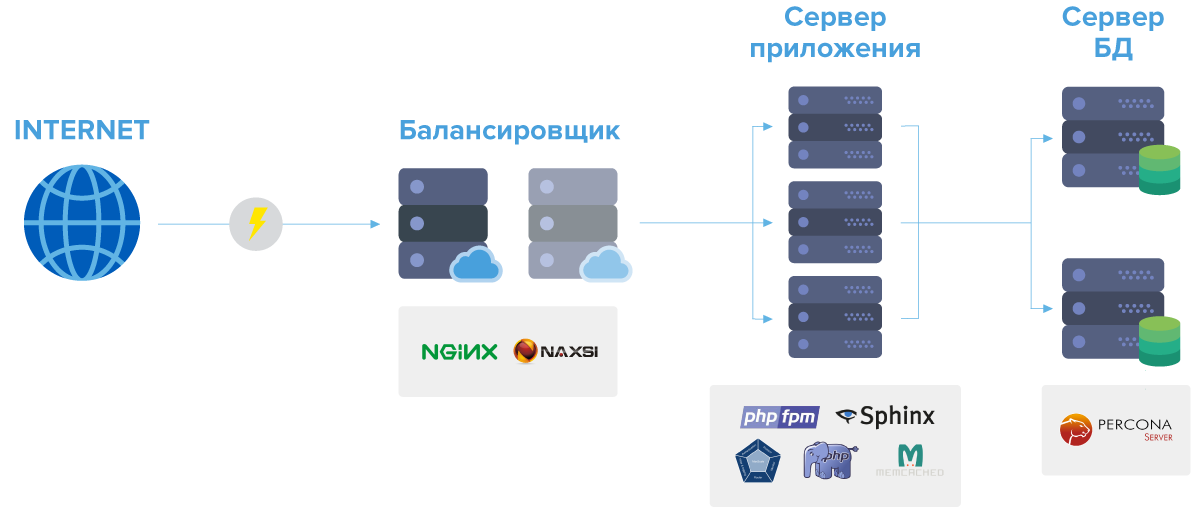
Схема серверов
3. Результаты сотрудничества
На примере реального проекта можно проследить, как описанный выше подход может привести в порядок даже очень запущенную систему.
Целью является крупный интернет-магазин мебели, построенный на CMS Bitrix.
Время генерации некоторых страниц на сайте достигало 200 секунд. Понятно, что при таких условиях пользователь никогда не дождется открытия страницы. Также на некоторых страницах количество запросов на хит достигало 20 000! На серверах, которым была отведена роль выполнения бизнес-логики были установлены разные версии PHP интерпретатора. Была реализована master-slave репликация, но по факту балансировка не была реализована и работал только один мастер. Данный факт говорил о том, что деньги, выплачиваемые за аренду мощного сервера, не приносили никакой пользы. Серверы БД находились в ДЦ, удаленном от всех других серверов проекта, что накладывало задержку на время соединения более 10 мс. Memcached, установленный на мастер-сервере БД использовался только для хранения сессий, а весь кэш хранился в файлах.
Парк серверов состоял из пяти довольно мощных машин. Под сервер, несущий на себе Nginx и выполняющий роль мастера для бизнес-логики был выбран вариант с параметрами Dell PowerEdge R730, снаряженный Intel Xeon E5-2600 v3 2.10GHz Octa-Core, 128 ГБ DDR4 ECC RAM. Этот сервер обрабатывал 90% всех запросов и судя по значению Load Average должен был гореть ярким факелом от перегрева. Мастер и слейв БД MySQL находились в виртуальных контейнерах на одном физическом сервере Dell PowerEdge R730. Как отмечалось ранее, слейв сервер просто реплицировал мастер и не нес никакой нагрузки, а значит ресурсы сервера, отведенные контейнеру со слейвом попросту не использовались. Под слейв серверы, выполняющие бизнес-логику использовались две машины с параметрами Intel Core i7-4770, 32 ГБ DDR3 и, можно сказать, не справлялись со своими обязанностями. Также довольно мощный сервер использовался для простого хранения бекапов. На всех серверах использовались SATA диски 6 Гбит/с 7200 об/мин.
В конечном итоге на большинстве серверов не было задействовано и 10% доступных вычислительных ресурсов.
Что было сделано
Было решено использовать новый парк серверов и развернуть там новую архитектуру, после тестирования “переехать” на новые серверы, а от старых отказаться. Оптимальный выбор серверов под каждую роль смог сократить расходы на их аренду. Серверы получились дешевле используемых ранее. Проанализировав размеры данных проекта, было принято решение использовать SSD диски. Они быстрее SATA аналогов и заметно ускоряют файловые операции. Особенно это важно на серверах баз данных. Под хранение бекапов был выделен отдельный сервер-хранилище в соседнем ДЦ. Каждый сервер являлся физической машиной. Виртуализация не использовалась.
Тезисно остановимся на каждой роли.
Балансировщик:
- собрана последняя стабильная версия nginx с дополнительными модулями;
- жестко структурированы файлы конфигураций;
- удален "мусор" и "мертвые" виртуальные хосты;
- реализована балансировка нагрузки на сервера приложений. В случае аварии на сервере приложения все "клиенты" передаются другому серверу. Если авария на 2-х серверах приложений, то некоторый трафик направляется на собственный сервер приложений балансировщика и система продолжает обслуживание;
- установлен WAF (Web Application Firewall) для защиты от XSS и SQL - инъекций
- настроена поддержка SSL;
- все выгрузки и обмены происходят на балансировщике, т.к. его ресурсы не заняты при штатном функционировании системы;
- полностью перенесены, переписаны и оптимизированы правила реврайтов из файлов .htaccess;
- балансировщик занимается изменением размеров, кэшированием картинок и добавлением водных знаков “на лету”.
Серверы приложений:
- в качестве fastCGI для php был выбран php5-fpm;
- используется новая (совместимая) версия php;
- используется прекомпилятор/кэшер кода php - OpCache;
- тонко настроена конфигурация production пула;
- на каждом сервере приложений есть свой memcached, sphinxsearch и maxscale.
Серверы БД:
- Серверы БД перенесены в один ДЦ с серверами приложений, что уменьшило накладные расходы на связь.
- На серверах настроена master-master репликация. Так как используется 2-е ноды вместо 3-х, то отключен кворум. Для избежания split-brain используется maxscale на серверах приложений. С его помощью реализуется логика master-slave. Slave является горячей заменой master'y и по сути не знает, что он Slave.
- Сделана тонкая настройка конфигурации серверов. Появился большой запас производительности.
- Все основные параметры серверов контролируются через систему мониторинга zabbix с оповещениями о нештатных ситуациях дежурному администратору. Параметры выполнения PHP контролируются через Pinboard.
Были переработаны нагружающие страницы и переписана часть компонентов системы. А в целом был проведен большой объем работы по оптимизации кода проекта.
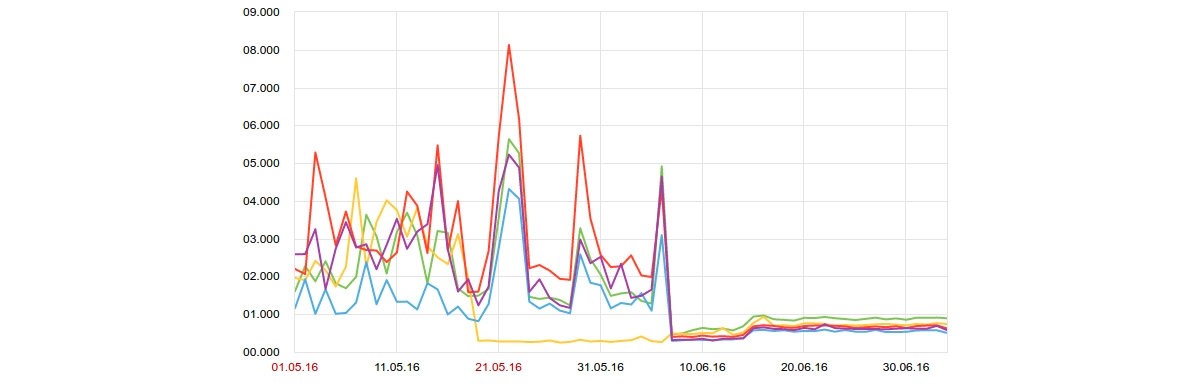
График времени загрузки страниц до и после проведенных работ

График нагрузочного тестирования после проведенных работ
4. Заключение
По результатам работ нам удалось достичь следующих показателей (см. график времени загрузки страниц до и после проведенных работ). В левой части графика отображена статистика по времени открытия страницы до переезда на новую архитектуру, в правой - после. Видно, что сейчас время полного открытия страницы находится в пределах 1 секунды. Это гарантирует комфортную работу с ресурсом для пользователей.
Из графика (см. график нагрузочного тестирования после произведенных работ) видно, что у ресурса есть проблемы с производительностью. Время полного получения страницы может достигать 8 секунд. Есть большая вероятность, что пользователь не дождется открытия этой страницы и уйдет.
Таким образом, сервис готов к резким всплескам нагрузки более чем в 2 раза.
Мы получили легко масштабируемую систему с хорошим уровнем отказоустойчивости и безопасности, готовую к резким всплескам нагрузки.
По воле случая, через неделю после переезда проекта на новую архитектуру проект был подвергнут массированной DDoS атаке в совокупности с другими способами достижения отказа в обслуживании. Это помогло нам найти скрытые узкие места и укрепить “оборону” сервиса тонкой настройкой критичных сервисов и операционной системы серверов.
И в заключении остановлюсь на очень важном моменте - резервное копирование. В данном проекте мы реализовали систему резервного копирования, которая резервирует базу данных на основе файлов и бинарных логов. Это позволяет быстро и незаметно для производительности сервера делать резервные копии. А главное, что это позволяет быстро восстанавливаться из этих копий. Резервное копирование файлов реализовано архивированием с созданием инкрементных копий, что позволяет минимизировать используемое место для хранения копий. Все резервные копии хранятся на выделенном сервере в соседнем ДЦ.
Агентство-исполнитель кейса
Интаро
Интаро разрабатывает интернет-магазины и веб-проекты под заказ, занимается сложной веб-интеграцией и автоматизацией. Разработка осуществляется или с использованием широко известной CMS "1С-Битрикс", или на основе фреймворка Symfony в зависимости от особенностей проекта. Ведется поддержка проектов на фреймворке yii. Некоторые наши проекты: Столплит, Связной, retailCRM, портал Государственной Думы.