
Авторизация
Сброс пароля
Снимаем нагрузку с менеджеров банка: автоматизация распознавания бухгалтерской отчетности
Вхождение в кейс дня
Заказчик: Госгарант

Чтобы снизить нагрузку на менеджеров банка, автоматизировали процесс обработки форм налоговой отчетности с помощью алгоритмов компьютерного зрения. MVP-версию продукта уже купил крупный федеральный банк.
Агентство-исполнитель кейса

Work Solutions
Кейс показывает, как на практике справились с нетривиальной задачей для компании из финансового сектора, соблюдая принципы прозрачности и котролируемости на всех этапах работы.

1. Вводная задача от заказчика, проблематика, цели
Консалтинговая компания «Госгарант» помогает банкам оперативно рассматривать сделки клиентов, проводить скоринг и принимать решения о представлении безотзывной гарантии победителям государственных тендеров. Взаимодействие с банками происходит в информационной системе FCS, которую разработала и семь лет сопровождает команда Work Solutions. За эти годы мы отгрузили 35000 коммерческих часов и выпустили 6 глобальных обновлений системы, а значит разбираемся в проекте как никто другой.
Раньше в систему FCS была интегрирована разработанная другим подрядчиком система распознавания документов. Она не распознавала формы бухгалтерской отчетности нового образца, работала медленно и давала высокий процент погрешности. Клиент решил не возобновлять сотрудничество с предыдущим исполнителем, и поручил нам разработку полной замены приложения.
Цель проекта — расширить функционал существующей системы, чтобы повысить ее ценность в глазах клиентов. Чем больше операций автоматизировано, тем выше вероятность, что банк захочет внедрить FCS у себя.
Задача — автоматизировать процесс обработки форм налоговой отчетности и снизить нагрузку на менеджеров банка. Увеличить таким образом скорость обработки заявок и, как следствие, повысить конверсию по выпуску банковских гарантий победителям гостендеров.
Пример диаграммы из предоставленного клиенту отчета

Три типа документов, которые нужно было распознать
2. Описание реализации кейса и творческого пути по поиску оптимального решения
АНАЛИТИКА
Прежде чем приступать к выполнению и начать расходовать деньги заказчика, нужно сперва понять, как решать поставленную задачу. На любом проекте по созданию ПО приходится сталкиваться с неизвестными факторами. Этап первичной аналитики позволяет рассмотреть несколько вариантов решения, а следовательно учесть ряд рисков на старте.
Даже обращаясь в продакшн, который специализируется исключительно на компьютерном зрении нужно быть готовым к тому, что разработчики запросят время на R&D (Research and development). Это связано с тем, что существует несколько подходов к решению, среди которых желательно выбрать оптимальный.
За это время разработчик проводит «спайк» (spike) — жестко ограниченное по времени исследование, на основе которого оценивает предстоящий объем работ. Результатом исследования также может быть минипроект, для подтверждения концепта (Proof of concept). Это позволяет убедится, что обнаруженные в ходе исследования подходы жизнеспособны и дает уверенность, что идея сработает.
Мы запросили у клиента три дня на анализ задачи. Для исследования нам предоставили набор реальных документов, которые нужно распознавать. Изучив десятки файлов, мы выделили три уникальные формы, которые требовали разного подхода при распознавании:
- Форма бухгалтерской отчетности старого образца;
- Машиночитаемая форма нового образца;
- Упрощенная форма сдвухмерным штрихкодом PDF417.
ПОТЕНЦИАЛЬНЫЕ ПРОБЛЕМЫ
Рассмотрев реальные документы мы также определили факторы, которые будут влиять на качество распознавания. На сканах часто встречаются артефакты — следы перфорации, пятна тонера, заломы, сгибы, подписи и печати, которые перекрывают текст. К тому же сами формы отсканированы неровно, в результате чего границы таблиц часто «обрезаны», а содержащийся в них текст наклонен.
Мы проверили возможность распознавания документа табличного типа и определили, с помощью каких инструментов можно это сделать. Далее изучили доступные решения, среди которых выделили опенсорсные инструменты и платные облачные сервисы, которые подходили для решения поставленной задачи. Затем провели небольшой бенчмарк и сравнили результаты их работы.
Полученную информацию в форме отчета предоставили заказчику, чтобы тот решил, стоит ли приступать к разработке. В итоге тарифные планы SaaS-сервиса оказались нерентабельными, поэтому заказчик попросил продолжить разработку.
ПЛАНИРОВАНИЕ
Так как на руках у нас было готовое исследование, этап планирования прошел легко. Для разработки выбрали следующий стек технологий:
- Python — язык программирования, который благодаря обилию доступных библиотек и поддержке многопоточности идеально подходит для решения подобных задач;
- Tesseract OCR — библиотека для оптического распознавания текстов, основанная на алгоритмах машинного обучения;
- OpenCV — библиотека алгоритмов компьютерного зрения;
- Django — фреймворк для создания веб-приложений.
Дорожную карту проекта привязали к типам документов и разделили на четыре двухнедельные итерации.
При подготовке к старту работ мы подняли инфраструктуру приложения, подготовили образы для Docker, настроили среду для разработки и развернули площадку на сервере заказчика для демонстрации. Таким образом мы сразу предоставили заказчику веб-интерфейс, чтобы видеть результаты работы в конце каждого этапа, а также доступ к таск-трекеру, чтобы отслеживать весь процесс.
РАЗРАБОТКА
Чтобы упростить предстоящую работу по распознаванию, начали с настройки предпроцессинга. Так как OpenCV работает только с растровыми изображениями мы настроили конвертацию многостраничных PDF в наборы JPEG-изображений. Для сканированных печатных документов настроили выравнивание структуры изображения по горизонтали, удаление шумов, дорисовку прерванных линий таблицы. Чем больше нежелательных артефактов удастся устранить, тем точнее система распознает текст.
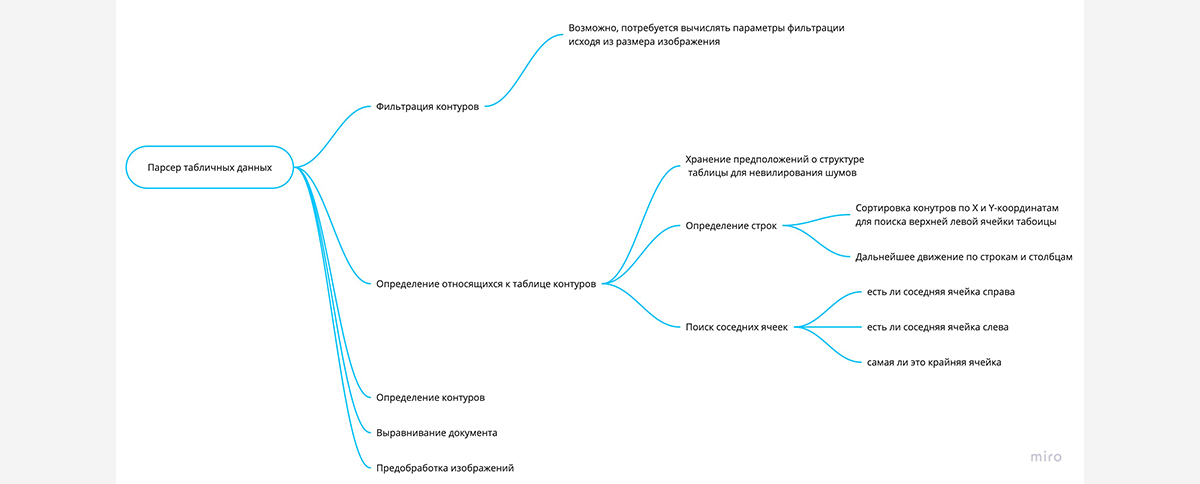
После этого приступили к распознаванию формы КНД старого образца. Проведенное ранее исследование показало, что линейность табличной структуры поможет распознать содержимое документа. Чтобы определить контуры таблицы преобразовывали входное изображение в двоичное и инвертировали цвет, получив черный фон и белые контуры.
Определив вертикальные и горизонтальные линии, накладываем их друг на друга. На получившемся изображении определяем контуры структуры таблицы. Все поля сортируем слева направо, и по координатам одну к другой подставляем ячейки. Таким образом, удается восстановить столбцы и строки.
Остается распознать содержимое отдельных ячеек. Для этого требуется найти отправную точку для X- и Y-осей. Находим ячейку, которая присутсвует на всех документах, а что находится за её пределами — отбрасываем. Фильтрация выделенных контуров позволяет сэкономить процессорное время на распознавание текста. Дальше сгруппированные ячейки нарезаем по координатам и передаем в Tesseract для распознавания текста.
Дополнительная сложность связана с тем, что числа представлены в разных форматах — где-то между цифрами стоят пробелы, а где-то запятые. Это как и артефакты нужно отсеять и предоставить в едином формате.
В результате генерируется JSON-файл с ID и хешем документа, которые хранятся в базе данных, чтобы можно было получить результата повторно. Внутри него также содержаться данные с координатами каждой ячейки, распознанные значения, прогноз погрешности (на основе того, как много дефектов было устранено во время препроцессинга) и изображение с этой областью. Оригинальное изображение ячейки нужно, чтобы человек мог проверить, не ошиблась ли машина.
В конце уже первой итерации было видно, что новая система работает эффективнее старой.
Второй спринт был нацелен на распознование документа с двухмерным штрихкодом PDF417. Так как документ содержит несколько штрихкодов, а распозновать требовалось только нижний внизу страницы, решили верхнюю половину документа не учитывать. У обычных штрихкодов много вертикальных линий, которые расположены плотно друг к другу. Такие контуры обнаружить гораздо проще, чем контуры штрихкода PDF417.
Для этого мы используем другой алгоритм: также сначала инвертируем цвета в градацию серого, а далее с помощью морфологических операций рассеиваем контуры, чтобы они не «прилипали» друг кдругу. После рассчитываем периметр контуров и отбираем среди них самые крупные. Определив контуры штрих кодов, нарезаем их на изображения и отправляем на распознавание библиотеке Zxing.
На этом этапе поступило дополнительное требование от заказчика, которое ранее не обсуждалось — потребовалось учитывать единицы измерений документов. К счастью, на каждой форме было отдельное поле с кодом, который отвечал за эту информацию. Мы точно знали, что есть два варианта: 384 для значений представленных в тысячах, а 385 — в миллионах.
К счастью это требование не существенно повлияло на ход разработки, и даже помогло при работе с последним типом документа — машиночитаемым. В начале новой итерации приступили к распознаванию отчетности нового образца.
Новый тип КНД не содержит таблиц, поэтому алгоритм поиска линейно структурированных столбцов уже не подходил. Такие документы знакомы, каждому кто сдавал ЕГЭ: на них нет четких линий, только пунктирные.
Решили отталкиваться от слова «Код», которое послужило точкой начала координат. Для этого учли все варианты написания слова. Далее с помощью морфологической операции отсекаем тексты, размытые ячейки, штампы, крупные штрихкоды. Все контуры отсекаем по оси X и Y, как и при работе с табличными документами. Далее оставшиеся контуры собираем в блоки по координатам, таким образом восстанавливам линейную структуру с подобием строк и столбцов. Нарезанные участки распознаваем через Tesseract.
В итоге удалось распознать все формы и сервис был почти готов — оставалось только оптимизировать работу.
ОПТИМИЗАЦИЯ ПРОИЗВОДИТЕЛЬНОСТИ
Приложение работало последовательно и очень медленно. Было много вычислений, которые зависели от скорости центрального процессора (CPU-bound). В итоге библиотеки OpenCV и Tesseract потребляли много ресурсов.
Чтобы ускорить систему вынесли обработку документа в отдельные параллельные процессы с многопоточностью, которую поддерживает Python.
Текущая реализация работает так, что предпроцессинг в первую очередь определяет, что перед ним — текст или изображение. После этого убирает шумы и запускает распознавание единиц измерения и тип документа, после чего понятно, какой алгоритм следует запустить. Таким образом документы стали распознаваться в десятки раз быстрее.

1. Исходное изображение 2. Выравнивание таблицы 3. Восстанавление прерванных линий 4. Устранение шумов

1. Исходное изображение 2. Рассеивание контуров 3. Определение штрихкода

1. Исходное изображение 2. Определение ячеек 3. Распознавание содержимого ячеек
3. Результаты сотрудничества
Сервис предстоит интегрировать с существующей CRM-системой, создать для него полноценное фронтенд-приложение с удобным пользовательским интерфейсом. Но конкретная цель проекта уже достигнута. Всего за полтора месяца работы одного программиста заказчик получил MVP-версию продукта, которую уже купил крупный федеральный банк.
4. Заключение
Надеемся, этот материал послужит понятной иллюстрацией принципов и подходов к проектной работе в Work Solutions и наглядно покажет, как достигаются цели бизнеса с помощью разработки программного обеспечения. Спасибо за внимание!
Агентство-исполнитель кейса
Work Solutions
Кейс показывает, как на практике справились с нетривиальной задачей для компании из финансового сектора, соблюдая принципы прозрачности и котролируемости на всех этапах работы.