
Авторизация
Сброс пароля
Обработка гигантского числа упоминаний мобильного оператора Т2 и конкурентов

1. Вводная задача от заказчика, проблематика, цели
О заказчике
T2 — федеральный оператор мобильной связи с абонентской базой 48,9 млн клиентов в 70 регионах России, включая MVNO-проекты группы «Ростелеком». Компания занимает лидирующие позиции в отрасли по показателям NPS, Value for Money и релевантности продуктовых предложений, что делает бренд заметным и активно обсуждаемым в публичном поле.
В 2025 году T2 одновременно решала задачи масштабного технологического развития (импортозамещение, расширение покрытия, VoLTE и VoWiFi), запуска новых бизнес-направлений (AdTech, финтех-сервисы, кибербезопасность) и укрепления лидерства на рынке MVNO. Такая высокая операционная и продуктовая активность усилила информационную нагрузку на бренд и сделала управление репутацией в цифровых каналах одним из ключевых факторов устойчивости бизнеса.
Контекст проекта
В 2025 году российский телекоммуникационный рынок замедлил рост до +6,5% (против +7,8% в 2024)*, достигнув объёма около 2,3 трлн рублей. На фоне насыщения B2C-сегмента, роста тарифов и удорожания инфраструктуры конкуренция между операторами усилилась, а внимание аудитории сместилось с цены на качество сети, клиентский сервис и доверие к бренду. В условиях, когда на одного пользователя приходится почти две SIM-карты, любое отклонение в пользовательском опыте мгновенно становится предметом публичного обсуждения.
Параллельно резко выросло количество и интенсивность дискуссий об операторах в социальных сетях, мессенджерах и на пользовательских платформах. Блокировки звонков в мессенджерах, изменения тарифов, внедрение новых сервисов и ограничения мобильного интернета усилили чувствительность аудитории к коммуникациям брендов. Репутация оператора всё чаще формируется не через рекламные сообщения, а через массовое цифровое обсуждение, где скорость реакции и точность информации критически важны.
*Источник: исследование Nexign и TelecomDaily 2025.


2. Описание реализации кейса и творческого пути по поиску оптимального решения
Для решения задачи T2 привлекла digital-агентство Fistashki. Уже на старте стало очевидно: классические ORM-подходы не масштабируются под такой объём данных.
Мы понимали, что при таких объёмах данных ручная разметка неэффективна, а стандартные автотеги и классические классификаторы дают лишь базовый уровень анализа. Эти инструменты хорошо работают для первичной фильтрации, но не позволяют глубоко учитывать контекст, нюансы тональности и смысловые оттенки, критичные для управления репутацией.
Даже сложные ML-модели хорошо работают на больших массивах, но всё ещё ограничены в глубине понимания смыслов. Для управления репутацией этого недостаточно — особенно если нужно ловить сигналы кризисов на ранней стадии.
Наш подход
Мы перешли к использованию больших языковых моделей (LLM), дообученных на собственной выборке и адаптированных под задачи репутационного анализа. Это позволило работать не просто с тональностью, а с качественными смыслами, контекстами и нюансами обсуждений.
Ключевой инструмент — Airis
Главную роль в проекте сыграл Airis — AI-стартап и внутренняя разработка агентства Fistashki.
Airis — это система интеллектуальной обработки упоминаний, работающая на базе пяти Large Language Models и выполняющая качественную разметку сообщений.
Сергей Максименко
Руководитель отдела репутации, Fistashki
Когда мы начали работать с таким объёмом данных, стало очевидно: классические ORM-инструменты перестают масштабироваться. Автотеги и базовые классификаторы отлично справляются с первичной фильтрацией, но практически не учитывают контекст. Для управления репутацией именно он критически важен.
Наша задача была перейти от механической логики “если А, то Б” к системе, которая способна анализировать сообщения так, как это делает человек: понимать смысл, улавливать оттенки тональности и видеть реальные причины обсуждений. Именно поэтому мы начали строить архитектуру анализа вокруг больших языковых моделей, которые позволяют работать с содержанием коммуникации


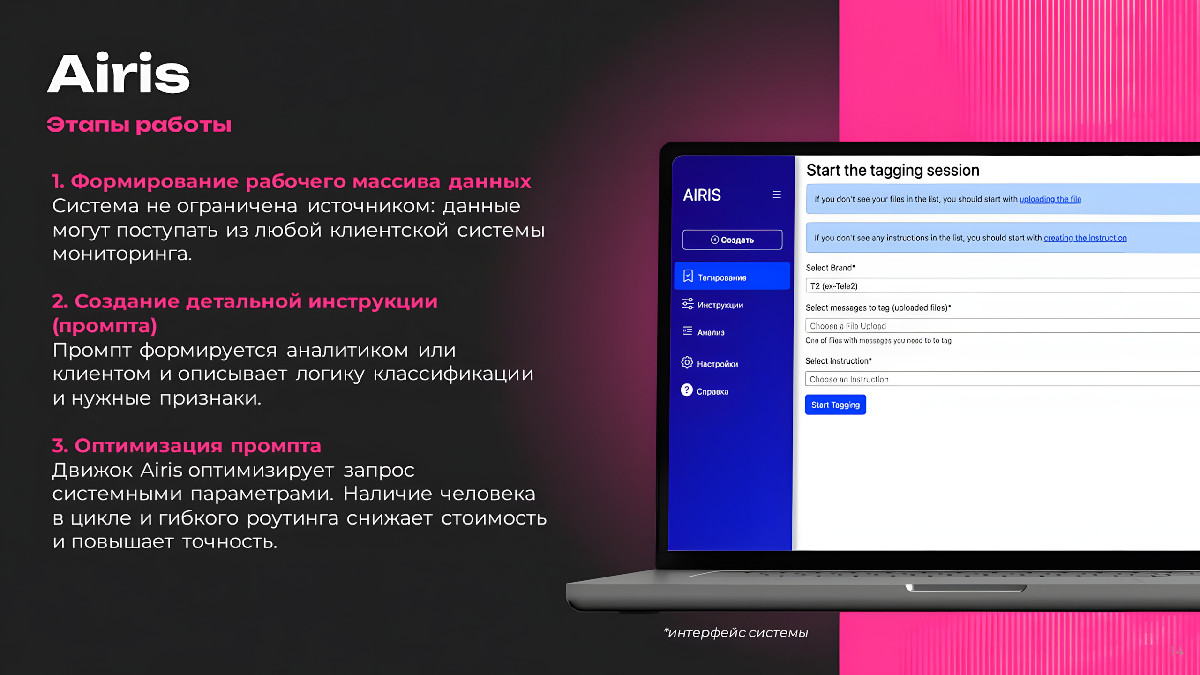
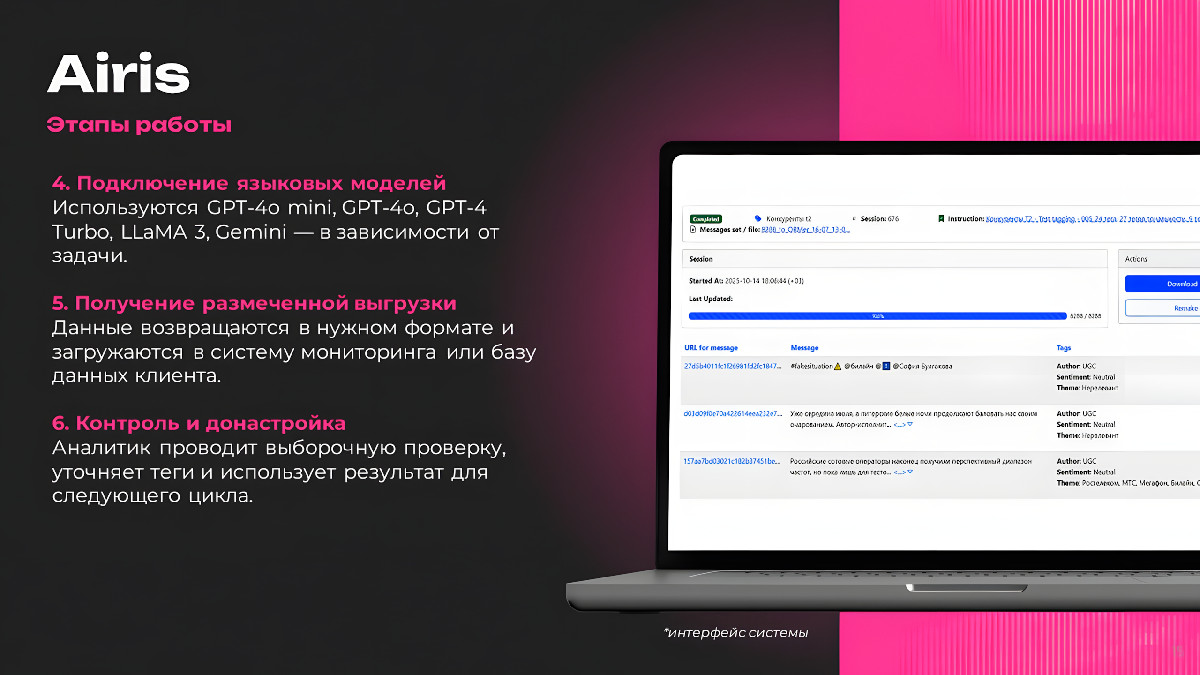
3. Результаты сотрудничества
Проект подтвердил эффективность выбранного подхода и дал заказчику реальное, управляемое понимание репутации бренда.
Ключевые результаты:
- обработка до 1 000 000 сообщений в месяц;
- в пиковые периоды — до 100 000 сообщений в день;
- 90–95% точности классификации;
- стабильная работа с инфополем T2 и ключевых конкурентов.
Главный эффект — масштабируемый ORM-процесс, который не ломается при росте упоминаемости и позволяет принимать решения на основе данных, а не выборочных сигналов.
Новаторство:
- использование LLM в ORM не как эксперимента, а как решения;
- отказ от жёсткой привязки к автотегам и классическим классификаторам;
- гибридный подход «AI + аналитик», где человек отходит от рутинных процессов и управляет логикой инструмента.
Качество исполнения:
- высокая скорость обработки без потери глубины анализа;
- адаптация под специфику телеком-отрасли;
- прозрачный и воспроизводимый процесс.

4. Заключение
Почему этот кейс достоин звания «Кейс года»
1. Кейс решает реальную рыночную проблему значимого масштаба, а не локальную задачу.
2. Кейс демонстрирует новый стандарт ORM для крупных брендов.
3. Кейс показывает, как AI может усиливать аналитику, а не заменять экспертизу.
4. Результат применим и масштабируем для всей отрасли.
Социальная миссия
Кейс T2 показывает, как технологии помогают брендам быть более ответственнымии внимательными к своим аудиториям даже в условиях информационного шума и перегрузки.
Герман Прохоренко
Руководитель группы по работе с социальными медиа, Т2
Ручная обработка такого объема сообщений существенно увеличила бы затраты на блок работ по ORM. Предложенное агентством решение помогло нам эффективно использовать ресурсы и включать человека для калибровки инструментов аналитики и точечных работ со сложными и неоднозначными кейсами.

Сергей Максименко
Руководитель отдела репутации, Fistashki
Ручная разметка сообщений — это тот тип работы, от которого индустрия постепенно уходит. При объёмах инфополя, которые сегодня формируются вокруг крупных брендов, такой подход становится просто экономически неэффективным.
Использование LLM позволяет обрабатывать огромные массивы данных с высокой точностью и при этом существенно сокращать потребность в ручном труде. Для нас это не просто технологический эксперимент, а шаг к новому стандарту ORM, где специалисты сосредоточены на стратегии и аналитике, а рутинные операции выполняет интеллектуальная система
