
Авторизация
Сброс пароля
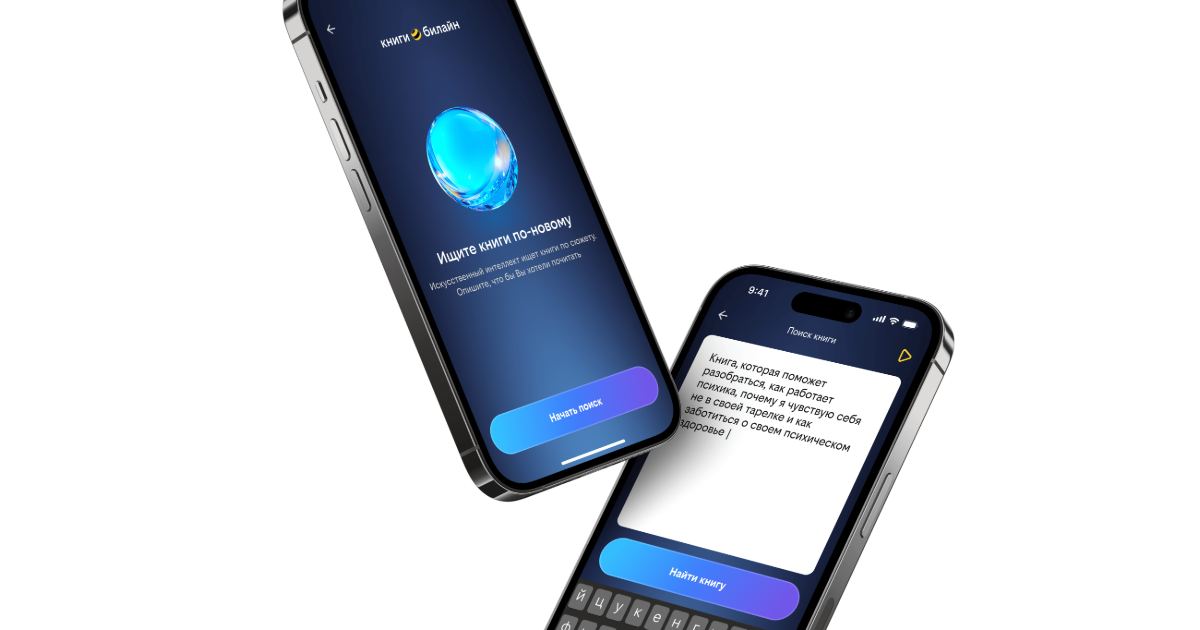
книги билайн — цифровая библиотека книг с умной системой рекомендаций
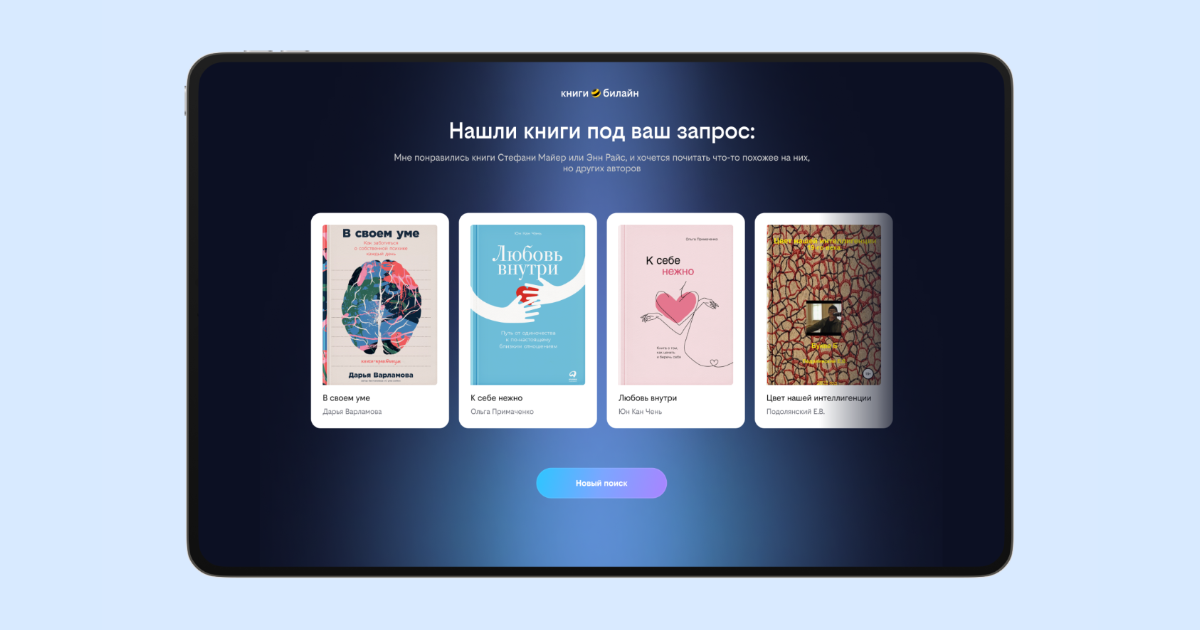
1. Вводная задача от заказчика, проблематика, цели
Рынок цифровых книг устроен однотипно: у сервисов схожие каталоги и базовый набор функций — чтение, прослушивание и синхронизация между устройствами. В таких условиях главным конкурентным преимуществом становится внимание пользователя.
Команда сервиса «книги билайн» провела внутреннее исследование и получила инсайт: 54% пользователей затрудняются выбрать книгу, если они не знают конкретного автора или названия. Большинство формулирует запросы через ощущения: «лёгкое чтиво на вечер», «история о сильной женщине», «нуарный детектив с харизматичным героем» или «что-то вроде „Сумерек“, но менее наивное».
На основе инсайта, полученного из исследования, команда сформулировала гипотезу – если научить AI понимать смысл свободных пользовательских запросов и обеспечить достаточную релевантность ответов, можно:
- сделать поиск книг более удобным – сократить путь пользователя от запроса до подходящей книги
- раскрыть потенциал всего каталога (500 000+ книг)
- повысить вовлечённость читателей и глубину взаимодействия с сервисом
- включить в потребление более широкий ассортимент — предлагать релевантные, но неочевидные книги
- повлиять на конверсию и удержание пользователей (LTV)
Команда книги билайн первой в индустрии решила научить AI работать со смыслом художественных текстов, а не просто искать по ключевым словам. Для этого нужно было выстроить инфраструктуру, которая анализирует контент и метаданные: авторов, жанры и аннотации.
На этом этапе к проекту подключился red_mad_robot . Мы отвечали за архитектуру, обработку данных и разработку гибридного поиска на основе LLM и векторной базы. Перед нами стоял вызов — за два месяца построить систему, которая сопоставляет абстрактные запросы на естественном языке с каталогом из более чем 500 000 произведений.
Мы создали первую в России гибридную AI-систему смыслового поиска. Она превращает эмоции и настроения читателя в точные рекомендации, помогая растить число подписок и глубину взаимодействия с сервисом.
2. Описание реализации кейса и творческого пути по поиску оптимального решения
Читатели описывают книги через эмоции: «что-то вроде „Сумерек“, но менее наивное». Такие ассоциации нельзя напрямую связать с метаданными — автором или жанром. Нам нужно было создать систему, которая понимает свободные описания без точных названий и автора.
На реализацию проекта отвели восемь недель: две на подготовку и шесть на разработку. Готовых стандартов для таких AI-решений на рынке не было, поэтому многие подходы мы выстраивали с нуля. Для этого собрали компактную кросс-функциональную команду из шести человек.
В основе решения — гибридный анализ: сочетание классических NLP-методов и семантического поиска на базе LLM. По аналогии с филологическим анализом, где смысл раскрывается через лексику, структуру и контекст, мы учили систему «понимать» книги через многослойное сопоставление данных.
Ранние прототипы показали: ни LLM, ни чисто векторный поиск по отдельности не дают точных результатов. Поэтому мы их объединили. Теперь LLM анализирует смысл запроса, а векторная база находит совпадения по контенту и метаданным.
Параллельно мы столкнулись с проблемой: цензурные фильтры LLM блокировали ответы на запросы о преступлениях или романтике. Но без них невозможно представить ни один детектив. Чтобы система работала корректно, мы перенастроили промпты и фильтры.
Финальная архитектура состоит из двух контуров:
LLM: разбирает запрос пользователя на параметры — жанр, настроение, тематику, тип персонажей — и определяет стратегию поиска.
Векторная база данных: ищет совпадения по каталогу из более чем 500 000 книг. В базе хранятся метаданные: от авторов до эмоциональной тональности сюжета.
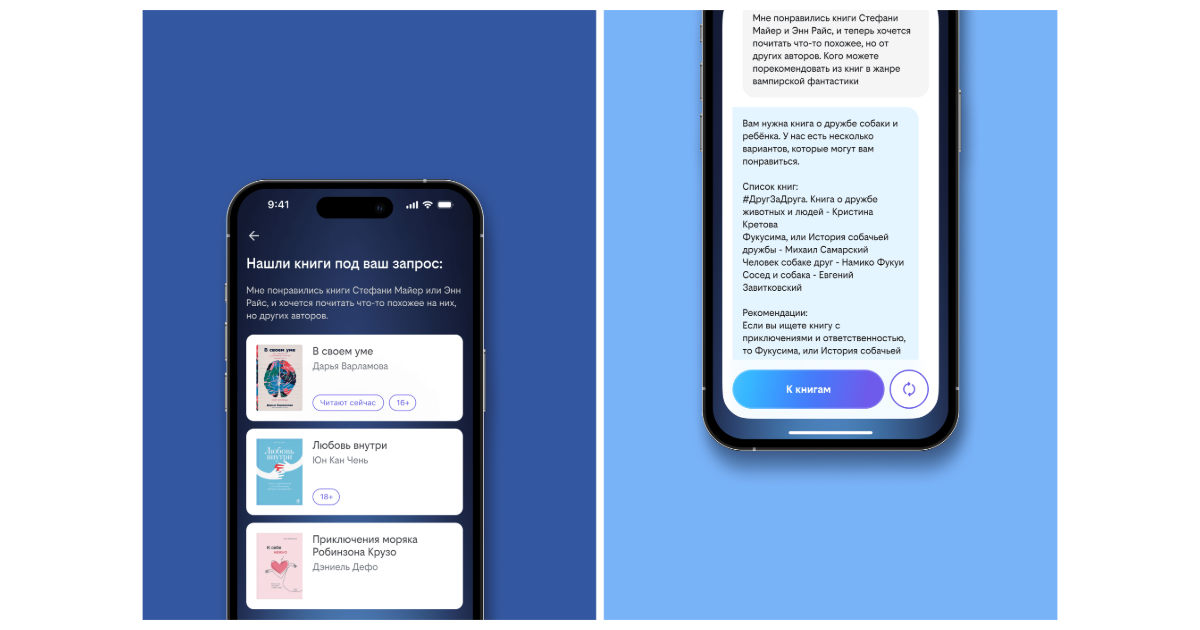
Затем LLM повторно ранжирует результаты семантического поиска и формирует ответ на естественном языке. Благодаря связке двух систем выдача становится точнее: нейросеть учитывает не только слова, но и смысл произведений. Такая схема объединила глубину анализа LLM и масштабируемость векторных моделей.
На следующем этапе мы оптимизировали генерацию ответов: вместо обычного текста стали запрашивать у LLM структурированные данные (Structured Output) в формате JSON:
[{"book": "book_1", "author": "author_1"}, {"book": "book_2", "author": "author_2"}]
Такой формат позволил автоматически проверять через API сервиса, какие из предложенных книг реально присутствуют в каталоге «книги билайн». После валидации нейросеть повторно ранжирует список с учётом данных из векторной базы и выдаёт пользователю итоговый текст. Так система рекомендует только те произведения, которые реально доступны в сервисе.
Тесты показали: поиск по аннотациям не всегда точен. Часто аннотация — это маркетинговый текст, который плохо отражает содержание. Поэтому в следующей версии мы с командой билайна планируем перейти на анализ логлайнов — кратких структур с местом действия, персонажами и фабулой. Это сделает смысловой поиск ещё точнее.
В декабре 2024 года сервис открыли для всех пользователей. Из-за сжатых сроков первоначально мы выпустили веб-версию умного поиска отдельно от основного приложения. После тестов мы проанализировали реальные запросы и поведение читателей — эти данные помогли наметить план доработок.
В первый месяц сервис получил 1,1 млн просмотров страниц поиска и 520тыс. уникальных пользователей. Это фактически весь активный рынок цифрового чтения. Рост числа подписок подтвердил: читатели быстро адаптировались к новому формату.
AI-поиск стал результатом совместной работы: «книги билайн» отвечали за идею и продукт, а red_mad_robot — за архитектуру и технологии. Проект показал синергию классического полнотекстового поиска и современных AI-подходов.
Почему проект взлетел:
- гибридная архитектура: объединили LLM, векторный поиск и NLP;
- обработка миллионов неструктурированных данных о книгах;
- система контроля галлюцинаций на основе реальных кейсов;
- работа в одной связке: объединили продуктовую стратегию Билайна и техническую экспертизу Робота.

Нам предстояло пройти четыре этапа проекта за два месяца
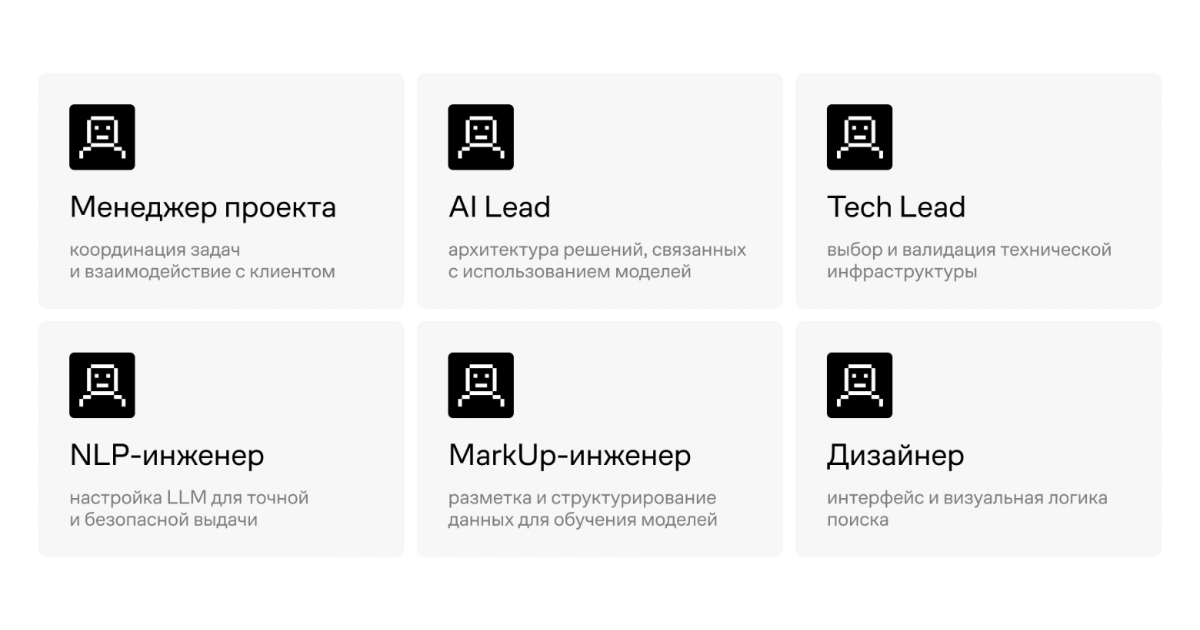
Команда по запуску AI-проекта не обязательно должна быть большой
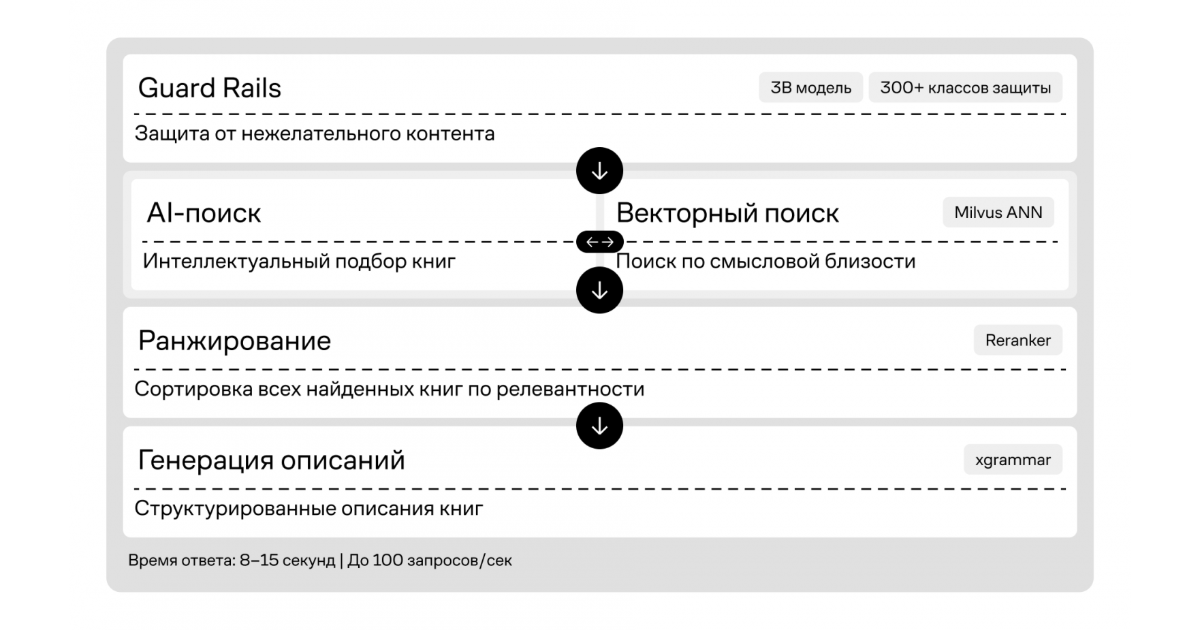
Схема работы умного поиска
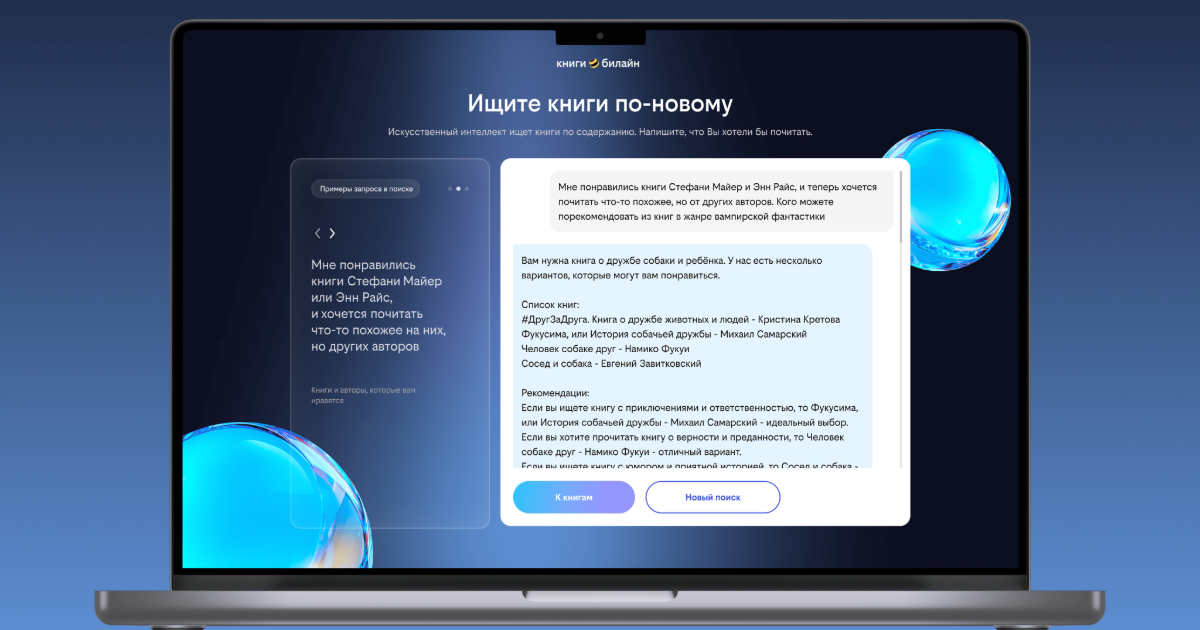
3. Результаты сотрудничества
За восемь недель команда red_mad_robot спроектировала и запустила первую в российской книжной индустрии систему гибридного AI-поиска по смыслу.
- Создана гибридная архитектура поиска, объединяющая LLM и векторную базу данных.
- Векторизованы метаданные каталога из 500 000+ книг по десяткам параметров.
- Разработан механизм Structured Output для валидации рекомендаций через API каталога.
- Внедрено двухэтапное ранжирование с весовыми коэффициентами.
- Запущена веб-версия AI-поиска для всех пользователей сервиса.
Рост числа подписок и глубины взаимодействия подтвердил: пользователи быстро адаптировались к новому формату.
- Скорость и нагрузка. Выдача ответа занимает 8–15 секунд. При этом система обрабатывает сто запросов в секунду и находит книги даже по самым необычным промптам.
- Работа с каталогом. Пользователи стали открывать книги, которые раньше оставались «невидимыми».
- Проверка гипотез. Новый формат подтвердил: смысловой поиск востребован читателями.
Проект стал примером быстрого вывода инновационного решения на рынок:
- MVP реализован за 2 месяца
- масштабирование началось сразу после первых пользовательских данных и подтвердило, что система не ограничена по количеству пользователей
- решение доступно всем пользователям (не только подписчикам)
- реализовано в веб-версии и Telegram-боте
За полгода после запуска удалось повысить общую эффективность сервиса до следующих показателей:
- x10 рост MAU — ежемесячной аудитории сервиса;
- +11% к ARPU — средней выручке на пользователя;
- +23% к оборачиваемости каталога — теперь каждое четвёртое произведение попадает в поисковую выдачу и читательский поток;
- x4 рост LT — среднего срока подписки клиента.
4. Заключение
На момент старта проекта ни один книжный сервис в России не предлагал поиск книг по неструктурированным, эмоциональным описаниям. Это не адаптация существующего решения, а создание нового продукта с нуля.
Решение, созданное совместно с командой книги билайн, стало первым примером гибридного AI-поиска, в котором нейросеть и семантический поиск работают параллельно. Система не просто ищет совпадения в словах, а анализирует смысл запроса: жанр, тему, стиль и настроение книги. Чтобы выдача была точной, мы настроили весовые коэффициенты для ранжирования результатов.
В основе проекта — сложная инженерная архитектура, в которой каждый AI-инструмент отвечает за свою задачу. Команда «Книг билайн» сформулировала идею и продукт, а red_mad_robot спроектировал систему, готовую к масштабированию. Этот кейс — пример того, как классический полнотекстовый поиск и современные AI-подходы работают в синергии.
Яна Чеканова
менеджер проектов, red_mad_robot
Это был первый релиз AI-поиска в сервисе книги билайн. С момента запуска мы анализируем все запросы, которые поступают в систему от пользователей, чтобы оптимизировать поиск и повысить точность ответов.

Илья Филиппов
CEO, red_mad_robot AI
Наш проект с использованием возможностей нейросети GigaChat для усиления сервиса книги билайн — хороший пример синергии классических цифровых технологий — в частности, полнотекстового поиска, — и современных AI-подходов.
