
Авторизация
Сброс пароля
Интеллектуальная трансформация технической поддержки XNET
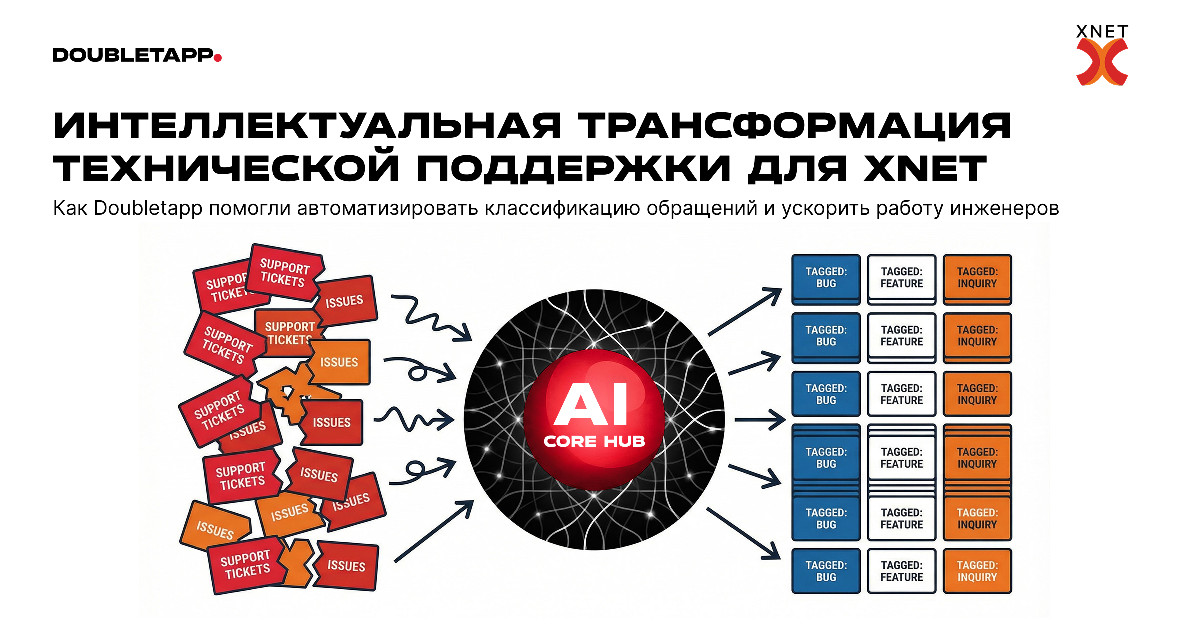
1. Вводная задача от заказчика, проблематика, цели
XNET — IT-компания из Казахстана, работающая по всему СНГ. Компания проектирует и внедряет IT-инфраструктуру, серверные решения, инженерные и сервисные системы, а также обеспечивает их дальнейшую техническую поддержку.
Каждый день служба поддержки XNET обрабатывает около 400 обращений: инциденты, запросы на обслуживание оборудования, консультации по эксплуатации и сложные технические вопросы.
На момент старта проекта:
- 25% обращений автоматически классифицировались другой системой,
- 25% отклонялись,
- 50% (около 200 обращений в день) требовали ручной классификации.
При этом:
- текущее время классификации могло достигать 10 минут;
- SLA на уведомление супервайзера составляло 8 минут;
- названия категорий были недостаточно информативны;
- структура категорий была иерархической и неравномерной (от >100 000 обращений в категории до единичных случаев).
Перед компанией стояли системные вызовы:
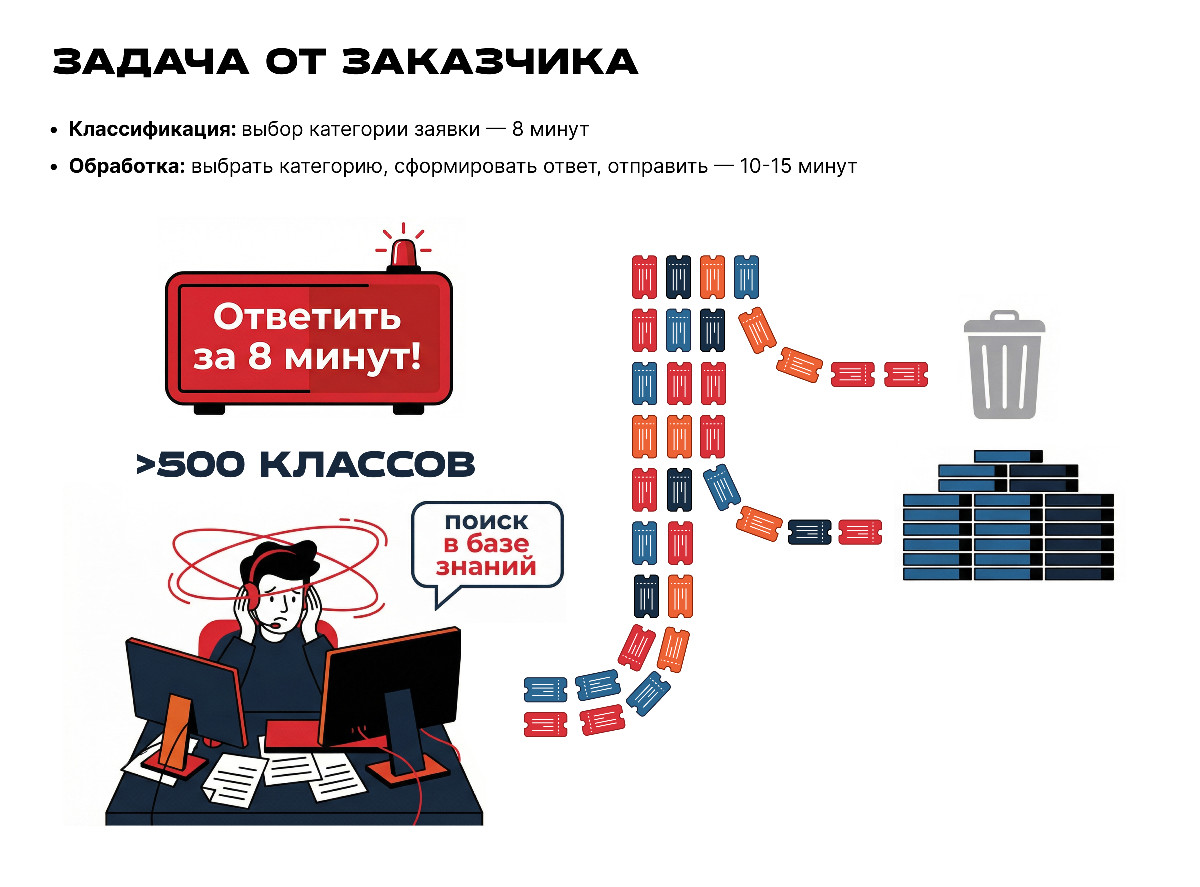
❌ обращения нужно вручную классифицировать на один из более чем 500 классов;
❌ распределение классов было неравномерным («длинный хвост»);
❌ чтобы ускорить обработку заявки, операторы иногда выбирали ближайшую понятную категорию;
❌ поиск информации для ответа занимал значительное время;
❌ масштабирование команды техподдержки требовало найма дорогих квалифицированных сотрудников.
Цель проекта:
✅ Автоматизировать классификацию обращений и сократить время обработки с 10 до 2 минут, создав масштабируемую архитектуру, работающую полностью внутри контура заказчика.
2. Описание реализации кейса и творческого пути по поиску оптимального решения
Проект был реализован в два этапа, каждый из которых усиливал предыдущий.
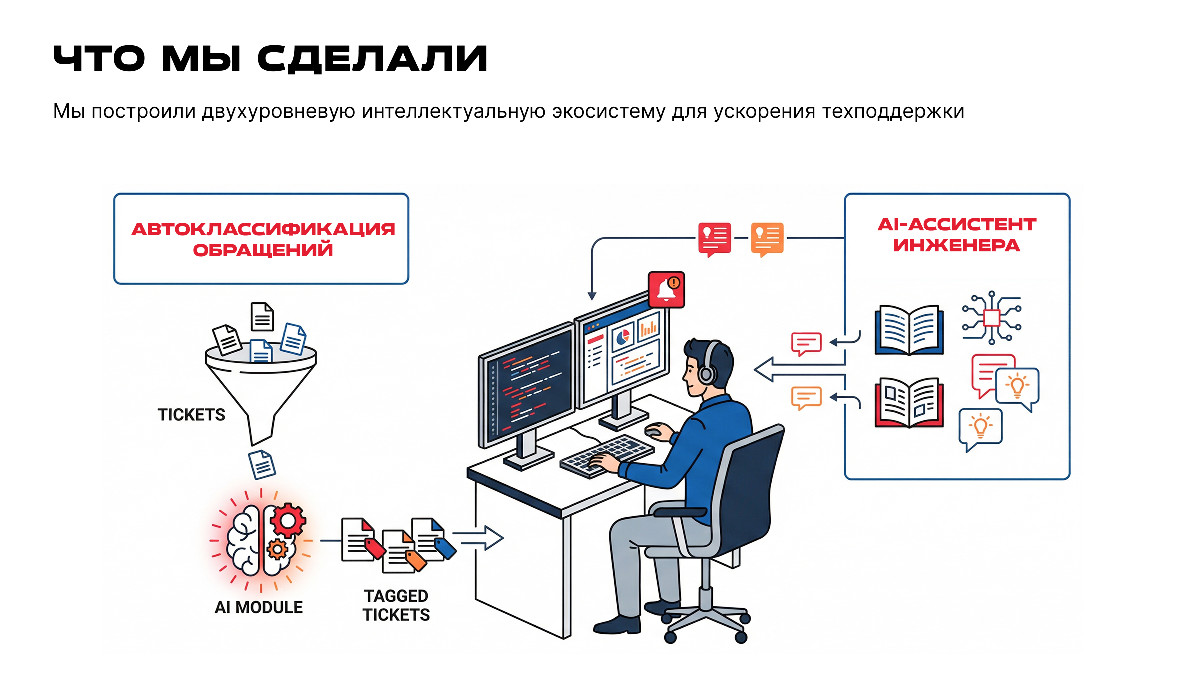
1. Мы автоматизировали классификацию обращений.
2. Создали интеллектуального ассистента для поиска информации в инструкциях и последующей генерации ответа.
Система реализована в виде микросервиса с API, интегрированного в существующую платформу заказчика.
Развертывание — on-premise: данные не покидают периметр компании, LLM запускается на GPU-серверах заказчика.
Проект 1. Автоматическая классификация обращений
➜ Проблема сложности
В системе поддержки XNET более 500 классов обращений с иерархической структурой.
Распределение обращений крайне неравномерное — одни категории содержат более 100 000 обращений, другие — единичные случаи.
Названия категорий оказались недостаточно информативными для языковой модели.
Кроме того, нужно было учитывать:
- источник обращения (влияет на приоритет),
- признак важности заявителя,
- список доступных категорий для конкретного заказчика.
Ранее тестировались классические алгоритмы машинного обучения, но качество оказалось недостаточным.
➜ Новая логика
Команда Doubletapp реализовала систему на базе LLM (большой языковой модели), развернутой в инфраструктуре заказчика. Для выбора оптимальной модели был проведен этап сравнительного тестирования.
Рассматривались локальные модели:
- Qwen 3 32B
- Mistral Small 3.1 24B
Оценка велась по стандартным метрикам:
- точность (precision),
- полнота (recall),
- F-мера.
Заказчик предоставил:
- накопленную базу обращений с правильной классификацией,
- примеры заявок с метаданными (текст, источник, важность),
- список доступных классов.
Дополнительно для каждого класса были созданы подробные текстовые описания с примерами типичных обращений, так как одних названий было недостаточно для корректной работы модели.
➜ Стратегии классификации
Мы протестировали два подхода.
➜ Подход 1. Все классы одновременно
Модель получает заявку и полный список доступных категорий с описаниями.
Плюс — полный контекст.
Минус — при большом количестве классов модель может терять фокус.
➜ Подход 2. Пакетная обработка
Категории разбиваются на группы примерно по 20 классов.
Модель проходит по группам, определяя релевантность, затем при необходимости делает финальный выбор.
В каждой группе присутствует категория «Не подходит».
Плюс — лучшая фокусировка.
Минус — потенциальное увеличение времени обработки.
По итогам этапа оценки была выбрана оптимальная конфигурация с учетом точности и времени ответа.
➜ Решение для пограничных ситуаций
Сложнее всего классифицировались обращения, которые можно было отнести к нескольким близким категориям.
Для повышения точности был добавлен механизм поиска похожих примеров:
- система ищет в базе похожие уже классифицированные обращения;
- передает их вместе с описанием классов в модель;
- принимает решение с учетом реальных аналогов.
Фактически реализована архитектура RAG, retrieval augmented generation — генерация с опорой на найденные данные, где retrieval — поиск похожих примеров.
Это позволило:
- повысить точность на редких категориях;
- снизить влияние «длинного хвоста»;
- уменьшить участие человека в рутинной маршрутизации.
Проект 2. Интеллектуальный ассистент для специалистов
Если первый проект автоматизировал распределение обращений, то второй ускорил сам процесс подготовки ответа.
➜ Подготовка базы знаний
Исходные инструкции хранились в формате HTML и содержали изображения.
Для корректной работы LLM мы:
- перевели инструкции в формат Markdown;
- создали текстовые описания всех изображений;
- добавили структурированную мета-информацию об организации;
- унифицировали структуру документов.
Это позволило создать машиночитаемую базу знаний, пригодную для семантического анализа.
➜ Гибридный поиск: смысл + точные термины
Была реализована гибридная система поиска:
- семантический поиск (по смыслу),
- поиск по ключевым словам (названия технологий, оборудования).
Результаты объединяются и «перевзвешиваются» — система выбирает наиболее вероятные документы. Это особенно важно в IT-среде, где одно точное название технологии может полностью изменить решение.
➜ Генерация ответа
Когда поступает запрос:
1. Система ищет релевантные документы.
2. Учитывает контекст обращения.
3. Передает набор документов вместе с запросом в LLM, развернутую во внутреннем облаке заказчика.
4. Формирует структурированный HTML-ответ.
5. Указывает источники инструкций.
Если ответа в базе нет, система может дополнительно обратиться к интеллектуальному интернет-поиску. Ассистент не заменяет специалиста — он экономит время и снижает зависимость результата от уровня экспертизы сотрудника.
Оценка качества: от синтетических тестов к реальной практике
➜ Этап 1. Создание системы тестирования
Была разработана автоматическая система оценки качества классификации и генерации ответов.
LLM генерировала тестовые вопросы:
- по фактам,
- по документам целиком,
- по описаниям изображений.
Метрики:
- найден ли правильный класс;
- позиция правильного класса в ранжировании;
- совпадение ответа с эталонным.
- Это позволило объективно выбрать модель и стратегию классификации.
➜ Этап 2. Проверка на практике
Уже при первом запуске системы обработки заявок порядка 90% ответов признаны полезными.
Система показала высокий уровень практической применимости.
3. Результаты сотрудничества
После внутренней презентации решение начало активно использоваться сотрудниками первой и второй линии поддержки.
Более 90% ответов операторы оценивают как качественные.
Дополнительно:
✅ система реализована как микросервис с API;
✅ развернута на инфраструктуре заказчика;
✅ модель работает на GPU внутри периметра компании;
✅ предусмотрена возможность администрирования классов через веб-интерфейс (админку);
✅ возможно тестирование новых категорий до ввода в промышленную эксплуатацию.
Система демонстрирует реальную прикладную ценность и потенциал масштабирования.
4. Заключение
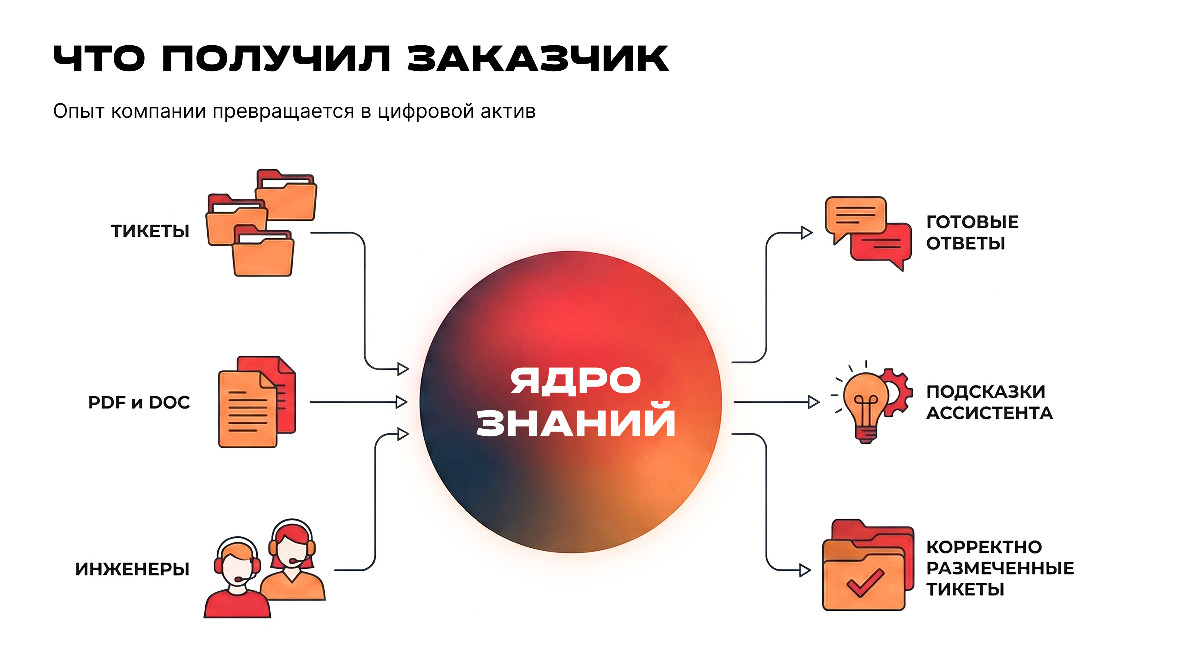
Проект для XNET стал не просто примером цифровизации бизнес-процессов, но и стратегическим шагом в развитии компании.
Новая система изменила саму логику работы технической поддержки: компания превратила накопленный опыт в управляемый цифровой актив, сделав базу знаний удобной и максимально доступной для всех сотрудников.
В результате XNET получила:
✅ устойчивую архитектуру, способную обрабатывать растущий объем обращений без пропорционального увеличения штата;
✅ сокращение времени на рутинные операции и высвобождение экспертов для решения действительно сложных задач;
✅ инструмент для ускоренного обучения новых сотрудников — система фактически передает им экспертизу компании в режиме реального времени;
✅ снижение зависимости качества сервиса от человеческого фактора.
Главное — компания создала экономическую основу для масштабирования.
Рост количества клиентов и проектов больше не требует линейного увеличения ресурсов. Снижение операционных затрат открывает новые управленческие возможности:
✅ гибко формировать ценовую политику для клиентов;
✅ повышать маржинальность проектов;
✅инвестировать высвобожденные ресурсы в развитие сервисов и технологий.
Таким образом, XNET получила не просто инструмент оптимизации процессов, а конкурентное преимущество. Синергия человека и интеллектуальных систем позволила компании выйти на новый уровень зрелости — когда технологии не догоняют бизнес, а опережают его и формируют пространство для роста.