Авторизация
Сброс пароля
Разработка AI-модуля для обработки фото для интернет-магазина Lamoda

1. Вводная задача от заказчика, проблематика, цели
Важная часть маркетинга в Lamoda — качественные фотографии в карточках товаров. Съемки проводят на собственной фотостудии полного цикла, ретушеры ежедневно обрабатывают огромное количество изображений, из которых нужно отобрать самые качественные, расположить объект в кадрах под правильными углами, улучшить фон. С помощью хороших фото магазин подчеркивает достоинства товара, дает покупателю изучить его со всех сторон.
Представители интернет-магазина обратились к нам, чтобы разработать ML-решение. Оно должно было снять с сотрудников рутинные, однотипные задачи по обработке фотографий — расположение объекта в кадре, коррекцию цвета фона и другие. Среди них был также поворот объекта на изображении без строго заданного угла: ретушеры справлялись с ним благодаря насмотренности. Эту задачу также нужно было передать нейросети: для этого подготовили базу уже обработанных фото.

2. Описание реализации кейса и творческого пути по поиску оптимального решения
Для карточек в каталоге Lamoda важна ориентация объекта в кадре — он всегда должен быть расположен в центре, на фоне с градацией светлых оттенков, иметь определенную тень. Поэтому для решения задачи заказчика мы использовали ансамбль из двух нейронных сетей:
- Первая осуществляет дихотомическую сегментацию изображений. В результате изображение разделяется на сегменты или области, которые считаются однородными по некоторым критериям, например, по цвету, текстуре или интенсивности. «Дихотомический» означает «разделяющийся на две части», так что этот метод сегментации часто включает рекурсивное разделение изображения на более мелкие области до тех пор, пока не будут выполнены определенные условия однородности.
- Вторая нейронная сеть, Deep-OAD — это модель глубокого обучения, которая определяет угол ориентации естественного изображения.
Также мы использовали набор морфологических операций библиотеки OpenCV для обработки разных ракурсов объекта — в профиль, сверху, и для поворота в пространстве.
Вид объекта в профиль
Изображение обуви в профиль загружается в сервис и автоматически обрабатывается нейросетью, которая отделяет объект от фона, добавляя альфа-канал для прозрачности.
Для этого используется набор операций, например, установка объекта на фон, установка белого фона, затемнение, которое улучшает контраст и яркость изображения, делает его более насыщенным и выразительным, коррекция фона для оптимизации освещения и теней на фоне, чтобы сделать изображение более естественным.
Вид объекта сверху
Изображение загружается по указанному пути, для его фона задается уровень белого. Используется модель сегментации объекта, добавляется альфа-канал и применяются такие операции, как коррекция поворота, коррекция наклона линии, позиционирование объекта.
После этого, как и при работе с видом в профиль, изображение преобразуется в маску, на нем устанавливается белый фон, производится затемнение фото и коррекция фона.
Обработка поворота обуви
Мы научили модель разворачивать обувь на изображении с помощью набора последовательных действий. Фото загружается по заданному пути, после этого нейросетевая модель Deep-OAD определяет необходимый угол, при котором обувь будет ориентирована корректно. После этого производится поворот, удаление фона, установка позиции объекта и применяются те же операции, как и при работе с видами сверху и в профиль: изображение преобразуется в маску, на нем устанавливается белый фон, производится затемнение фото и коррекция фона.
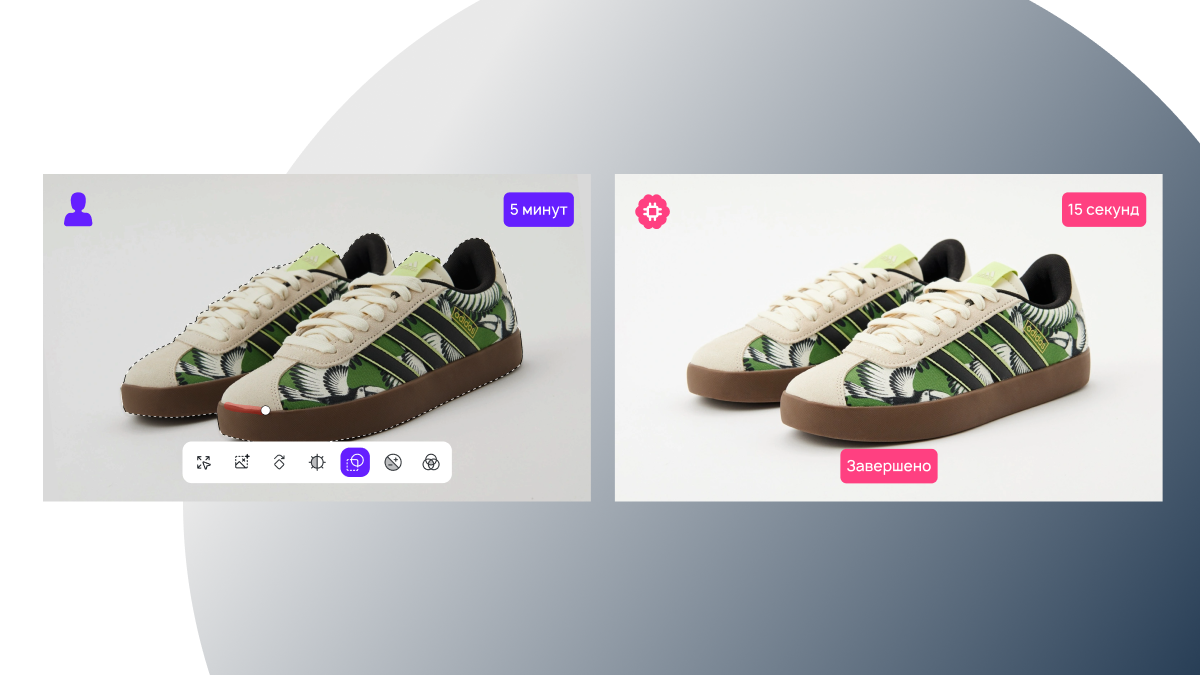

3. Результаты сотрудничества
Наш сервис ускорил процесс обработки фото, разгрузил сотрудников от однотипных задач. Теперь одно изображение приводится к правильному виду за 5–15 секунд, в зависимости от мощности процессора. Человеку на это требуется несколько минут. Сейчас мы продолжаем работу с Lamoda, добавляем новые функции, внедряем нейросеть, которая сортирует задачи и сразу направляет их в нужный модуль.
4. Заключение
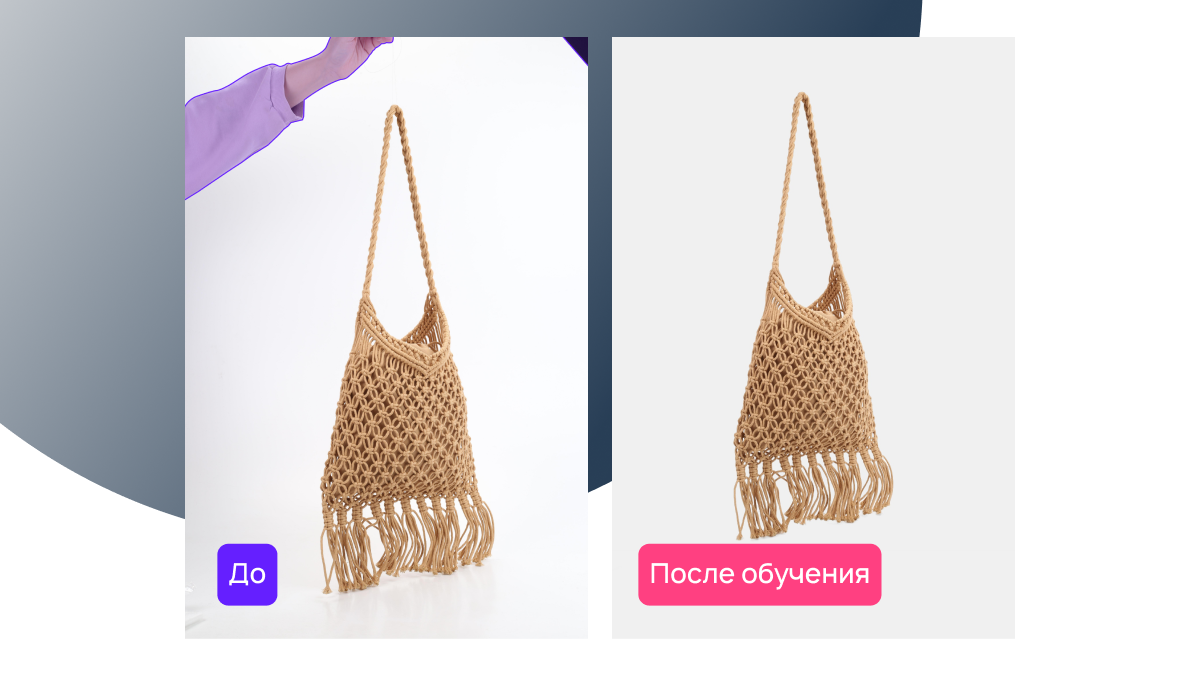
Мы продолжаем сотрудничество с Lamoda, например, добавляем новые типы объектов: после обуви мы научили AI-сервис обрабатывать фото сумок.
Работа с изображением сумки включает те же этапы, что и обработка фото обуви, но потребовала дополнительной тренировки нейросетевых моделей. Также мы обучили ещё одну AI-модель: она убирает руки из кадра.